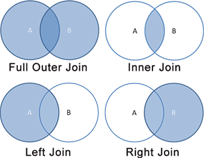
In this part we will see how to perform a Repartition Join in MapReduce. It is also called the Reduce-Side Join because the actual joining of data happens in the reducers. I consider this type of join to be the default and most natural way to join data in MapReduce because :
- It is a simple use of the MapReduce paradigm, using the joining keys as mapper output keys.
- It can be used for any type of join (inner, left, right, full outer …).
- It can join big datasets easily.
 We will first create a second dataset, “Projects”, which can be joined to the “Donations” data which we’ve been using since Part I. We will then pose a query that we want to solve. Then we will see how the Repartition Join works and use it to join both datasets and find the result to our query. After that we will see how to optimize our response time.
We will first create a second dataset, “Projects”, which can be joined to the “Donations” data which we’ve been using since Part I. We will then pose a query that we want to solve. Then we will see how the Repartition Join works and use it to join both datasets and find the result to our query. After that we will see how to optimize our response time.