Spark in a general cluster-computing framework, and in our case we will use it to process data from the Cassandra cluster. As we saw in Part I, we cannot run any type of query on a Cassandra table. But by running a Spark worker on each host running a Cassandra node, we can efficiently read/analyse all of its data in a distributed way. Each Spark worker (slave) will read the data from its local Cassandra node and send the result back to the Spark driver (master). 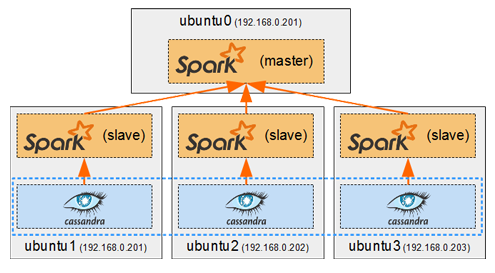
Tag: <span>Cassandra</span>
 In this part we will learn how to run Docker containers. We will explore the basic Docker commands while deploying a small Cassandra cluster on separate hosts on my cluster. To keep things simple we will use the official Cassandra image from Docker Hub to create the Cassandra containers. I will also explain a few basic Cassandra principles and keep it simple for people who have no knowledge of Cassandra.
In this part we will learn how to run Docker containers. We will explore the basic Docker commands while deploying a small Cassandra cluster on separate hosts on my cluster. To keep things simple we will use the official Cassandra image from Docker Hub to create the Cassandra containers. I will also explain a few basic Cassandra principles and keep it simple for people who have no knowledge of Cassandra.
 In my previous series of posts, I’ve focused on using distributed computing frameworks, Hadoop and Spark, which had to be manually installed on Ubuntu on my cluster nodes.
In my previous series of posts, I’ve focused on using distributed computing frameworks, Hadoop and Spark, which had to be manually installed on Ubuntu on my cluster nodes.
In this series of posts I will write about how to use Docker to achieve automated distribution-independent deployment of any type of services on my cluster.