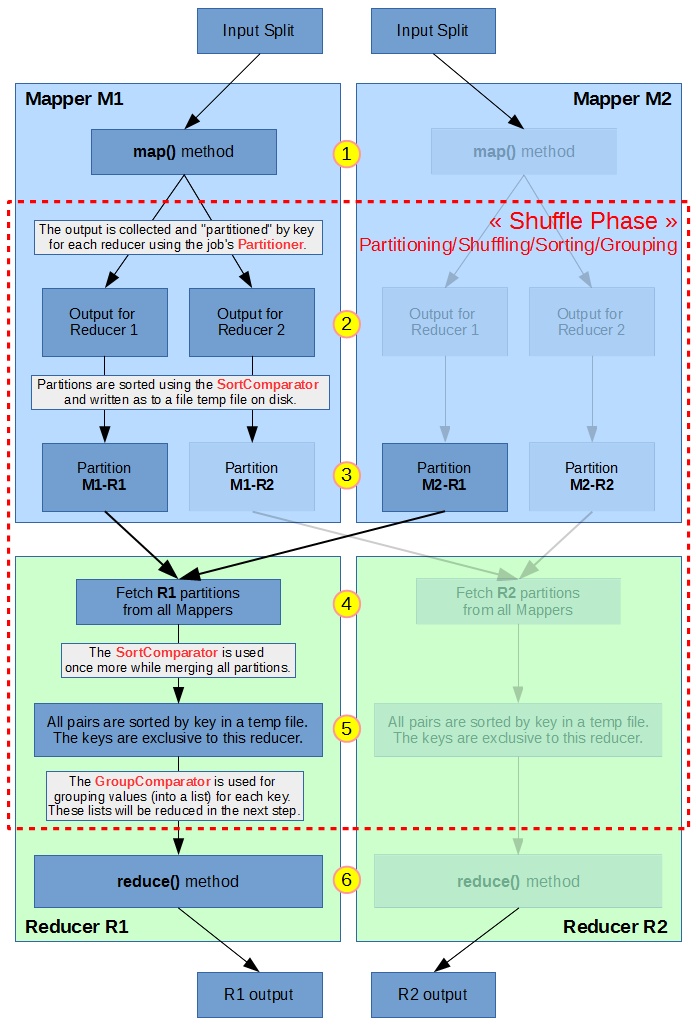
We saw in the previous part that when using multiple reducers, each reducer receives (key,value) pairs assigned to them by the Partitioner. When a reducer receives those pairs they are sorted by key, so generally the output of a reducer is also sorted by key. However, the outputs of different reducers are not ordered between each other, so they cannot be concatenated or read sequentially in the correct order.
For example with 2 reducers, sorting on simple Text keys, you can have :
– Reducer 1 output : (a,5), (d,6), (w,5)
– Reducer 2 output : (b,2), (c,5), (e,7)
The keys are only sorted if you look at each output individually, but if you read one after the other, the ordering is broken.
The objective of Total Order Sorting is to have all outputs sorted across all reducers :
– Reducer 1 output : (a,5), (b,2), (c,5)
– Reducer 2 output : (d,6), (e,7), (w,5)
This way the outputs can be read/searched/concatenated sequentially as a single ordered output.
In this post we will first see how to create a manual total order sorting with a custom partitioner. Then we will learn to use Hadoop’s TotalOrderPartitioner to automatically create partitions on simple type keys. Finally we will see a more advanced technique to use our Secondary Sort’s Composite Key (from the previous post) with this partitioner to achieve “Total Secondary Sorting“.

 In this part, we will run a simple Word Count application on the cluster using Hadoop and Spark on various platforms and cluster sizes.
In this part, we will run a simple Word Count application on the cluster using Hadoop and Spark on various platforms and cluster sizes.
