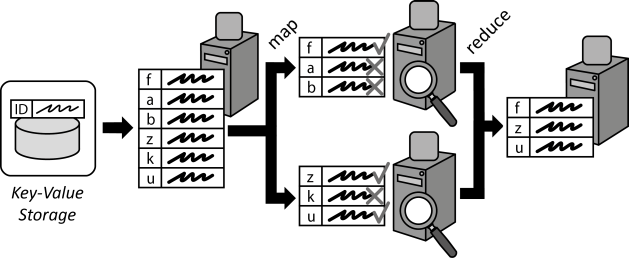
In the previous part we needed to sort our results on a single field. In this post we will learn how to sort data on multiple fields by using Secondary Sort.
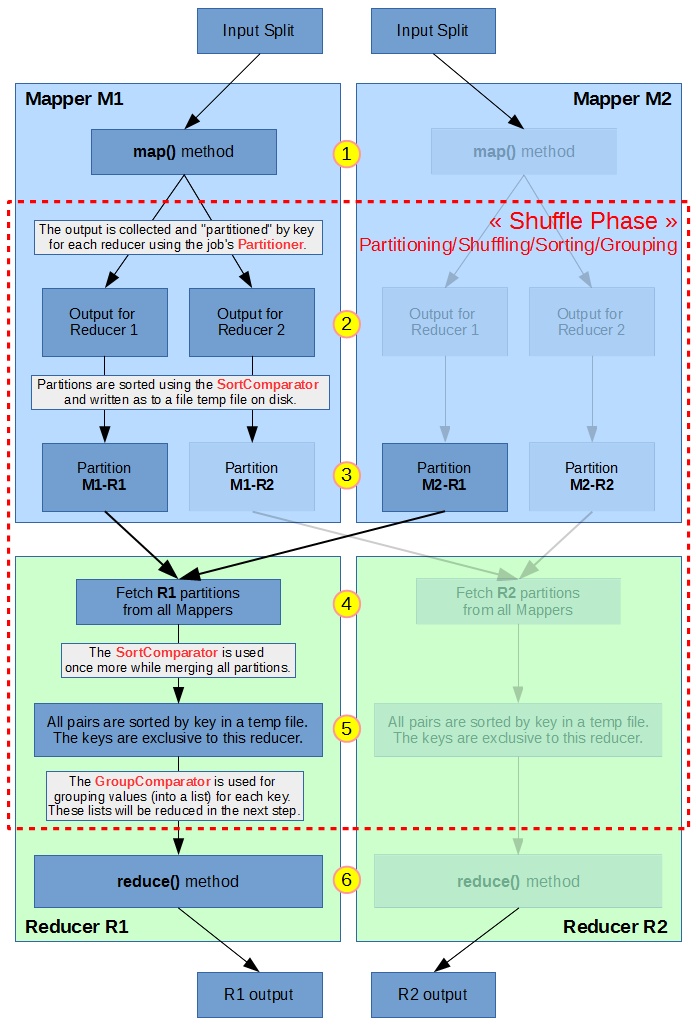
We will first pose a query to solve, as we did in the last post, which will require sorting the dataset on multiple fields. Then we will study how the MapReduce shuffle phase works, before implementing our Secondary Sort to obtain the results for the given query.