In the previous part we needed to sort our results on a single field. In this post we will learn how to sort data on multiple fields by using Secondary Sort.
We will first pose a query to solve, as we did in the last post, which will require sorting the dataset on multiple fields. Then we will study how the MapReduce shuffle phase works, before implementing our Secondary Sort to obtain the results for the given query.
Contents
The Query
This time let’s try to find the results to the following query :
View the id, donor’s state, donor’s city and total donation amount for all donations which have a defined state and city of origin. Order the results by priority of :
- State – ascending alphabetical order (case insensitive)
- City – ascending alphabetical order (case insensitive)
- Total amount – descending numerical order
This could be formulated in SQL as :
SELECT donation_id, donor_state, donor_city, total FROM donations WHERE donor_state IS NOT NULL AND donor_city IS NOT NULL ORDER BY lower(donor_state) ASC, lower(donor_city) ASC, total DESC;
Understanding the Shuffle Phase
In the MapReduce solution illustration in the previous post I represented the shuffle phase as a mysterious dashed box between the map and reduce methods. I also said that it sorts pairs automatically by key before giving them to the reducer, and we took advantage of that to sort our results.
Now we will need to look deeper into this mysterious box to understand :
- How and where it works
- What tools are available to customize and adapt it to our needs
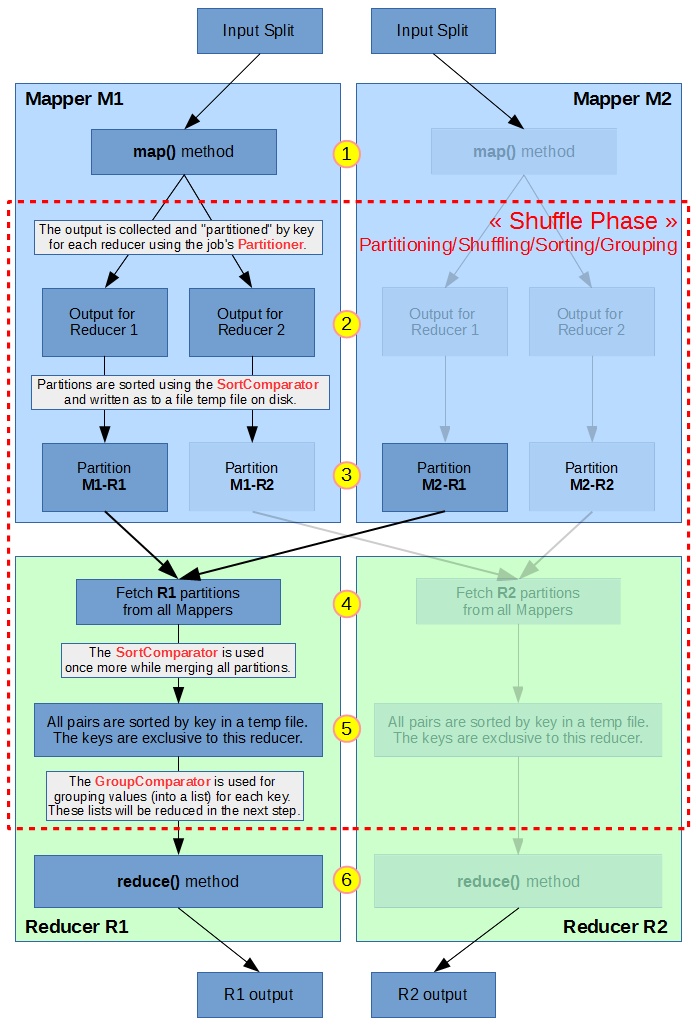
Below is a workflow chart using 2 mapper and 2 reducer tasks :
A few details on the different numbered steps :
- The map method from a mapper receives all (key,value) pairs from its split, provided by the InputFormat. This is the most important method that we usually code in a Mapper. In the previous part we filtered out and projected the input data in our implementation of this method.
- The outputs from the map method are partitioned for each user using the specified Partitioner. By default, the HashPartitioner is used in MapReduce. It uses the key’shashCode() value and perform a modulo on the number of reducers. This will randomize how the (key,value) pairs are stored in different partitions for each reducer based on the key. All pairs with the same key will be in the same partition and will end up in the same reducer.
- The data is sorted using the specified Sort Comparator the before being written to disk. The partitions are all written in a same temporary file.
- The reducers fetch all of their assigned partitions from all mappers. The partitions can either be written to a local temporary file, or stored in memory if they are small enough. This process is also known as “shuffling” because partitions are being shuffled around.
- The Sort Comparator is used again while merging all in-memory and on-disk partitions. Each reducer now has a fully sorted list of all (key,value) for all keys assigned to them by the partitioner.
- The Group Comparator is used to group values into a list. The reduce method will be called with parameters (key, list<values>) for each “different” key, according to the comparator’s definition of “same/different”.
In the previous part we only used 1 reducer, so there was no partitioning. We did not define a group comparator, so grouping was done naturally on Text equality (first job) and FloatWritable equality (second job). In the second job we defined a Sort Comparator to get a descending order on float values.
Secondary Sort
Secondary sort is a technique which can be used for sorting data on multiple field. It relies on using a Composite Key which will contain all the values we want to use for sorting.
In this section we will read our “donations” Sequence File, and map each donation record to a (CompositeKey, DonationWritable) pair before shuffling and reducing.
All classes used in this section can be viewed on GitHub in this package : https://github.com/nicomak/[…]/secondarysort.
The MapReduce secondary sort job which is executed to get our query results is in the OrderByCompositeKey.java (view) file from the same package.
Composite Key
Our query wants to sort the results on 3 values, so we create a WritableComparable class called CompositeKey (view) with the following 3 attributes :
- state (String) – This one will be used as our natural key (or primary key) for partitioning
- city (String) – A secondary key for sorting keys with same “state” natural key within a partition
- total (float) – Another secondary key for further sorting when the “city” is the same
Note : I implemented the compareTo() in this class, but it’s simply as default natural ordering, comparing all fields in ascending order. Our query wants to sort the “total” field in descending order, and for that we will create a specific Sort Comparator in the next paragraph.
Sort Comparator
As seen in the diagram, if we want our results to be ordered on all 3 attributes of the CompositeKey, we must use a Sort Comparator which orders by priority of [state,city,-total]. As we did in the previous part, we create a class which extends WritableComparator and implement the compare() method for our ordering needs :
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FullKeyComparator extends WritableComparator {
public FullKeyComparator() {
super(CompositeKey.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable wc1, WritableComparable wc2) {
CompositeKey key1 = (CompositeKey) wc1;
CompositeKey key2 = (CompositeKey) wc2;
int stateCmp = key1.state.toLowerCase().compareTo(key2.state.toLowerCase());
if (stateCmp != 0) {
return stateCmp;
} else {
int cityCmp = key1.city.toLowerCase().compareTo(key2.city.toLowerCase());
if (cityCmp != 0) {
return cityCmp;
} else {
return -1 * Float.compare(key1.total, key2.total);
}
}
}
}
We then set this class as the Sort Comparator with job.setSortComparatorClass(FullKeyComparator.class).
Mission accomplished ! Using a single reducer will now give us the fully sorted result. Implementing the Composite Key and Sort Comparator is enough to sort on multiple fields when using only one reducer.
Partitioner
But if we used multiple reducers, what would happen ? The default partitioner,HashPartitioner, would use the CompositeKey object’s hashcode value to assign it to a reducer. This would “randomly” partition all keys whether we override the hashcode() method (doing it properly using hashes of all attributes) or not (using the default Object implementation which uses the address in memory).
That wouldn’t be much of a secondary sort. Because after merging all partitions from mappers the reducer’s keys could be like this (first column) :
| What the reducer’s keys would be like | What we want, using correct partitioning | |
| Reducer 0 | [state=”CA“, city=”Los Angeles”, total=15.50] [state=”CA“, city=”Los Angeles”, total=2.00] [state=”CA“, city=”San Francisco”, total=21.35] … [state=”TX“, city=”Dallas”, total=5.00] [state=”TX“, city=”Houston”, total=10.00] |
[state=”AZ“, city=”Phoenix”, total=10.00] … [state=”TX“, city=”Dallas”, total=7.00] [state=”TX“, city=”Dallas”, total=5.00] [state=”TX“, city=”Houston”, total=10.00] |
| Reducer 1 | [state=”AZ“, city=”Phoenix”, total=10.00] [state=”CA“, city=”Los Angeles”, total=5.10] [state=”TX“, city=”Dallas”, total=7.00] |
[state=”CA“, city=”Los Angeles”, total=15.50] [state=”CA“, city=”Los Angeles”, total=5.10] [state=”CA“, city=”Los Angeles”, total=2.00] [state=”CA“, city=”Palo Alto”, total=4.00] [state=”CA“, city=”San Francisco”, total=21.35] |
| Reducer 2 | [state=”CA“, city=”Palo Alto”, total=4.00] | (other states than “CA“, “TX“, “NY“) |
In the first output column, within a reducer, the data from a given state are sorted by city name and then descending total donation amount. But this sorting doesn’t mean anything because some data is missing. For example Reducer 0 has 2 sorted Los Angeles keys, but the Los Angeles entry from Reducer 1 should have been between both.
So when using multiple reducers, what we want is to send all (key,value) pairs with the same “state” to the same reducer, as illustrated in the second column. The easiest way to do this is to create our own NaturalKeyPartitioner, similar to the default HashPartitioner, but based only the state’s hashcode, instead of the full CompositeKey’s hashcode :
import org.apache.hadoop.mapreduce.Partitioner;
import data.writable.DonationWritable;
public class NaturalKeyPartitioner extends Partitioner<CompositeKey, DonationWritable> {
@Override
public int getPartition(CompositeKey key, DonationWritable value, int numPartitions) {
// Automatic n-partitioning using hash on the state name
return Math.abs(key.state.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
We set this class as the job’s partitioner with job.setPartitionerClass(NaturalKeyPartitioner.class).
Group Comparator
The Group Comparator decides how values are grouped for each call to the reduce method.
Let’s use the example of Reducer 0 from the previous paragraph. If after merging its partitions, the (key,value) pairs that a reducer has to process are :
| Pair | Key (CompositeKey) | Value (DonationWritable) |
| A | [state=”AZ“, city=”Phoenix”, total=10.00] | DonationWritable@abd30 |
| B | [state=”TX“, city=”Dallas“, total=7.00] | DonationWritable@51f123 |
| C | [state=”TX“, city=”Dallas“, total=5.00] | DonationWritable@00t87 |
| D | [state=”TX“, city=”Houston”, total=10.00] | DonationWritable@057n1 |
The possible groupings that can be done are :
| Grouping | Calls to reduce(key, [values]) |
| Default | reduce(A.key, [A.value]) reduce(B.key, [B.value]) reduce(C.key, [C.value]) reduce(D.key, [D.value]) |
| Group by “state,city” | reduce(A.key, [A.value]) reduce(B.key, [B.value, C.value]) reduce(D.key, [D.value]) |
| Group by “state” | reduce(A.key, [A.value]) reduce(B.key, [B.value, C.value, D.value]) |
Exaplanations :
- There are no keys with the same combination of (state,city,total). So with the first grouping, the reduce method is called once for each record.
- The second grouping is by “state,city”. The keys from B and C pairs have the same state and same city, so they are grouped together for a single reducer() call. The key which is passed to the function is the key of the first pair of the group, so it depends on the sorting.
- The third grouping only looks at “state” values. All keys from B,C,D have the same state, so they are grouped together for a single call to reducer().
Grouping can be useful in some cases. For example, if you can to print the sum of all total donations for a given city next to each donation output, you can use the second grouping from the example above. Doing that, you could sum all “total” fields in the reduce() function before writing out all values.
For our query we only need to print out fields from each record, so grouping doesn’t matter. Calling the reduce() function 4, 3 or 2 times will still result in simply printing out the (id, state, city, total) fields for A,B,C and D records. For this job it did not have any influence on the performance.
Let’s group by “state” (natural key), just for the sake of using our own Group Comparator :
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class NaturalKeyComparator extends WritableComparator {
public NaturalKeyComparator() {
super(CompositeKey.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable wc1, WritableComparable wc2) {
CompositeKey key1 = (CompositeKey) wc1;
CompositeKey key2 = (CompositeKey) wc2;
return key1.state.compareTo(key2.state);
}
}
We can then use this comparator by calling job.setGroupingComparatorClass(NaturalKeyComparator.class).
Job Execution and Results
The following jobs were run on my mini cluster of 1 master and 4 slave nodes, with 2 GB of RAM each, allocating 1 GB containers for mappers and reducers. The input “donations” Sequence File that we created in part I was split into 4 HDFS blocks, so 4 mappers are running for this job.
Job 1 : With a single reducer
The job executed here is the one from my GitHub repository, in the OrderByCompositeKey.java class (view).
Console output
$ hadoop jar donors.jar mapreduce.donation.secondarysort.OrderByCompositeKey donors/donations.seqfile donors/output_secondarysort $ hdfs dfs -ls -h donors/output_secondarysort -rw-r--r-- 2 hduser supergroup 0 2015-12-28 16:00 donors/output_secondarysort/_SUCCESS -rw-r--r-- 2 hduser supergroup 74.6 M 2015-12-28 16:00 donors/output_secondarysort/part-r-00000 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | head -n 8 c8e871528033bd9ce6b267ed8df27698 AA Canada 100.00 6eb5a716f73260c53a76a5d2aeaf3820 AA Canada 100.00 92db424b01676e462eff4c9361799c18 AA Canada 98.36 e0f266ed8875df71f0012fdaf50ae22e AA Canada 1.64 d9064b2494941725d0f93f6ca781cdc7 AA DPO 50.00 83b85744490320c8154f1f5bcd703296 AA DPO 25.00 7133a67b51c1ee61079fa47e3b9e5160 AA Fremont 50.00 f3475f346f1483dfb57efc152d3fbced AA Helsinki\, FINLAND 153.39 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | tail -n 8 10df7888672288077dc4f60e4a83bcc2 WY Wilson 114.98 0b4dda44ac5dc29a522285db56082986 WY Wilson 100.00 4276bc7e6df5f4643675e65bb2323281 WY Wilson 100.00 519da9b977281b7623d655b8ee0c8ea5 WY Wilson 91.47 92469f6f000a6cd66ba18b5fe03e6871 WY Wilson 23.32 f0a9489e53a203e0f7f47e6a350bb19a WY Wilson 1.68 8aed3aba4473c0f9579927d0940c540f WY Worland 75.00 1a497106ff2e2038f41897248314e6c6 WY Worland 50.00
Result Analysis
Since only 1 reducer was use, there is only 1 output file. The file starts with state “AA”, which is not a USA state, but seems to regroup foreign cities. The file ends with “WY” (Wyoming) cities Wilson and Worland. Everything is sorted as requested in the query.
Job 2 : With 3 reducers, using default partitioner
This time we use 3 reducers by setting job.setNumReduceTasks(3) and we comment the job.setPartitionerClass(NaturalKeyPartitioner.class line to see what happens.
Console output
$ hadoop jar donors.jar mapreduce.donation.secondarysort.OrderByCompositeKey donors/donations.seqfile donors/output_secondarysort $ hdfs dfs -ls -h donors/output_secondarysort -rw-r--r-- 2 hduser supergroup 0 2015-12-28 15:36 donors/output_secondarysort/_SUCCESS -rw-r--r-- 2 hduser supergroup 19.4 M 2015-12-28 15:36 donors/output_secondarysort/part-r-00000 -rw-r--r-- 2 hduser supergroup 38.7 M 2015-12-28 15:36 donors/output_secondarysort/part-r-00001 -rw-r--r-- 2 hduser supergroup 16.5 M 2015-12-28 15:36 donors/output_secondarysort/part-r-00002 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | tail -n 5 234600cf0c052b95e544f690a8deecfc WY Wilson 158.00 10df7888672288077dc4f60e4a83bcc2 WY Wilson 114.98 0b4dda44ac5dc29a522285db56082986 WY Wilson 100.00 4276bc7e6df5f4643675e65bb2323281 WY Wilson 100.00 1a497106ff2e2038f41897248314e6c6 WY Worland 50.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00001 | tail -n 5 a31e6d2ddcffef3fb0c81a9b5be8a62b WY Wilson 177.60 ab277b46c65df53305ceee436e775f86 WY Wilson 150.00 519da9b977281b7623d655b8ee0c8ea5 WY Wilson 91.47 92469f6f000a6cd66ba18b5fe03e6871 WY Wilson 23.32 8aed3aba4473c0f9579927d0940c540f WY Worland 75.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00002 | tail -n 5 db2334f876e2a661dc66ec79b49a7073 WY Wilson 319.44 f740650269f523ac94a8bc54c40ffcb8 WY Wilson 294.70 dfdba1ed68a130da5337e28b45a469d1 WY Wilson 286.64 e5cf931220ab071083d174461ef50411 WY Wilson 278.19 f0a9489e53a203e0f7f47e6a350bb19a WY Wilson 1.68
Result Analysis
By looking at the last 5 lines of each output, we can notice that all outputs have entries with the Wilson city. Two of the outputs have entries with Worland city.
As explained earlier, the results in each output is correctly sorted with ascending state and city, and descending donation amount. But it’s impossible to view all sorted donations for a given state or city, since they are spread across multiple files.
Job 3 : With 3 reducers, using NaturalKeyPartitioner
For this job we simply reposition the job.setPartitionerClass(NaturalKeyPartitioner.class) command to use our custom Partitioner, while keeping the 3 reducer tasks.
Console output
$ hadoop jar donors.jar mapreduce.donation.secondarysort.OrderByCompositeKey donors/donations.seqfile donors/output_secondarysort $ hdfs dfs -ls -h donors/output_secondarysort -rw-r--r-- 2 hduser supergroup 0 2015-12-28 16:37 donors/output_secondarysort/_SUCCESS -rw-r--r-- 2 hduser supergroup 23.2 M 2015-12-28 16:37 donors/output_secondarysort/part-r-00000 -rw-r--r-- 2 hduser supergroup 22.8 M 2015-12-28 16:37 donors/output_secondarysort/part-r-00001 -rw-r--r-- 2 hduser supergroup 28.7 M 2015-12-28 16:37 donors/output_secondarysort/part-r-00002 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | tail -n 5 eeac9e18795680ccc00f69a42ec4fbc5 VI St. Thomas 10.00 634f02e6ffc99fddd2b2c9cda7b7677c VI St. Thomas 10.00 9f71710178a4fab17fb020bc994be60b VI Zurich / Switzerland 75.00 f81b2dc07c0cc3ccea5941dc928247a5 VI Zurich / Switzerland 50.00 8337fac8a67e50ad4a0dfe7decc4b8e9 VI Zurich / Switzerland 50.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00001 | tail -n 5 9f3ea230d660a20ec91b287b8a0f6693 WI Wrightstown 5.00 8b95de5d2b2027c0a3d2631c9f0f6f9b WI Wrightstown 5.00 9db66b1c0c71dd438a8f979dd04cdfb8 WI Wrightstown 5.00 c7c60406d260915cb35a7e267c28becc WI Wrightstown 5.00 c2d98a640c301cf277247302ad5014ca WI Wrightstown 5.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00002 | tail -n 5 519da9b977281b7623d655b8ee0c8ea5 WY Wilson 91.47 92469f6f000a6cd66ba18b5fe03e6871 WY Wilson 23.32 f0a9489e53a203e0f7f47e6a350bb19a WY Wilson 1.68 8aed3aba4473c0f9579927d0940c540f WY Worland 75.00 1a497106ff2e2038f41897248314e6c6 WY Worland 50.00
Result Analysis
Compared to the outputs of Job 2, we can see that only one reducer (r-00002) has the entries from “WY” state (Wyoming). So if you are only interested in donations coming from Wyoming, the results you are looking for is complete and correctly sorted in a single file.
Other reducer outputs end with different states (“VI” and “WI”) because each state is exclusive to a reducer. This is because we told our NaturalKeyPartitioner to consider the “state” field as the decisive value for partitioning.
Performance Comparison
Here is a table of comparison of the 3 jobs described in this section.
The total time was taken from the Resource Manager UI. The other values were taken from the MR History Server UI.
All metrics were averaged on 2 executions.
| Total time | Avg. Mapper time | Avg. Reducer time | |
| Job 1 | 3 min 20 s | 1 min 13 s | 1 min 42 s |
| Job 2 | 2 min 40 s | 1 min 17 s | 46 s |
| Job 3 | 2 min 30 s | 1 min 11 s | 54 s |
We can observe a significant improvement of total execution time when using 3 reducers. Jobs 2 and 3 are faster than Job 1.
In jobs 2 and 3 there are longer shuffling/merging times for each reducer but the actual reduce time in a lot shorter.
Conclusion
In this part we learned how to use some tools to have more control on partitioning, sorting and grouping during the shuffle phase.
We saw how to implement a Secondary Sort, which helped us :
- Fully sort a dataset on multiple fields – when using a single reducer
- Sort records with a same natural key on secondary keys – when using multiple reducers.
Using multiple reducers can speed up the sorting process, but at the cost of having only partially sorted natural keys across reducers.
New Definition
With hindsight, looking back at the effects of the different tools we applied on our Composite Key, we can give a more general yet precise definition to Secondary Sort, other than “sorting on multiple fields” :
Secondary Sort is a technique to control how* a reducer’s input pairs are passed to the reduce function.
*how = in which order (Sort Comparator) and which way of grouping values based on key (Group Comparator)
Based on this definition, using Secondary Sort we have total control on the data within a reducer, and that is why the outputs files were always internally sorted.
What Next ?
Using Secondary Sort we have control on the data within a reducer, but we can’t control how sorted map outputs are distributed to reducers yet. We have defined a partitioner to make sure that the different reducers manage their own natural keys and maintain coherent ordering on secondary keys. But it didn’t solve the problem of having all natural keys sorted across all outputs.
In the next post, we will learn how to do that with Total Order Sorting.
The best blog. Ultimate . May god bless you.
Thanks ! I’m glad you liked it. Amen.
This is one of the best article that explains this complex concept. I appreciate your time and effort.
By far the best explanation of this I’ve ever read. Thanks for your clear and thorough writing – it was very helpful for me.