Spark in a general cluster-computing framework, and in our case we will use it to process data from the Cassandra cluster. As we saw in Part I, we cannot run any type of query on a Cassandra table. But by running a Spark worker on each host running a Cassandra node, we can efficiently read/analyse all of its data in a distributed way. Each Spark worker (slave) will read the data from its local Cassandra node and send the result back to the Spark driver (master). 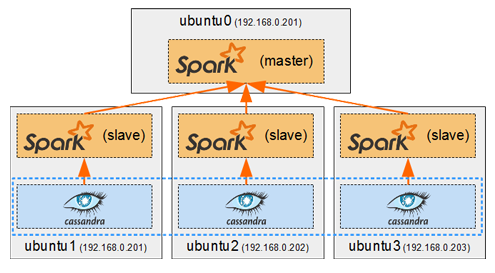
Contents
The Docker Image
Image source code: https://github.com/nicomak/[…]/spark
Image on DockerHub: https://hub.docker.com/r/nicomak/spark/
No official image exists for Spark so we need to create our own image. The image I created is very basic, it is simply a Debian with Python base image on top of which I’ve installed a Java 8 JDK. And the Spark 2.0.1 binaries are simply extracted from the original release tarball to the /app/ folder.
There is just a small subtlety for running the container. The Spark startup scripts run in background mode, so they cannot be used as the main container process, otherwise the container would die immediately. The main process of the container is the entrypoint.sh script, and to keep it alive forever I simply run tail -f the log folder. This way the logs are also written to the standard output and can be seen when running docker logs <container>.
Another problem is port mapping. Spark opens a lot of random ports to communicate between master and slaves. This is difficult to manage with Docker, so will simply use the –net=host network mode to let the containers open any port they want on the host.
Running the Spark Containers
We will install the Spark containers on top of our existing Cassandra cluster from Part I, as illustrated in the introduction above.
To start a cluster with the master (driver) on ubuntu0 and slaves (workers) on ubuntu[1-3]:
dock@ubuntu0:~$ docker run -d --name sparkmaster --net=host -e ROLE=master nicomak/spark:2.0.1 dock@ubuntu1:~$ docker run -d --name sparkslave --net=host -e ROLE=slave -e MASTER_URL=spark://ubuntu0:7077 nicomak/spark:2.0.1 dock@ubuntu2:~$ docker run -d --name sparkslave --net=host -e ROLE=slave -e MASTER_URL=spark://ubuntu0:7077 nicomak/spark:2.0.1 dock@ubuntu3:~$ docker run -d --name sparkslave --net=host -e ROLE=slave -e MASTER_URL=spark://ubuntu0:7077 nicomak/spark:2.0.1
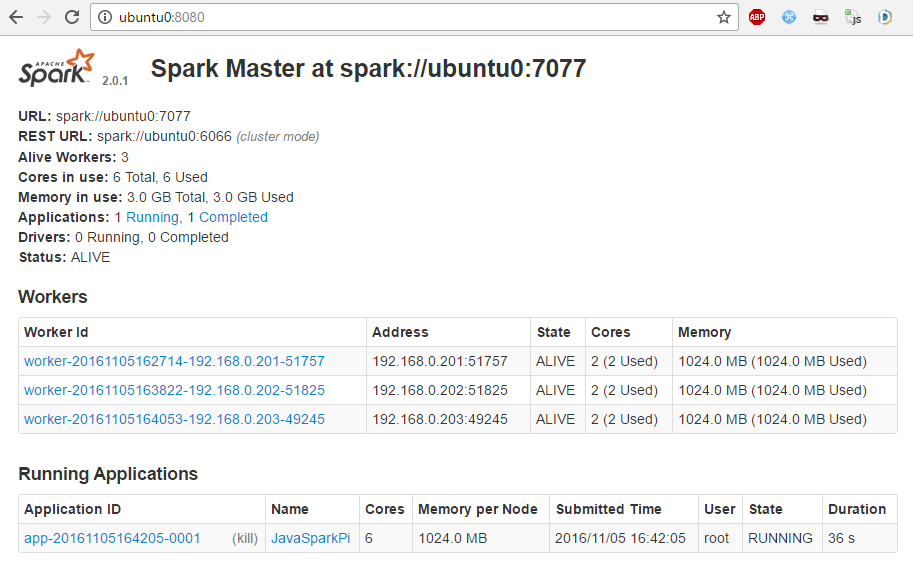
After starting them, the master UI should show all connected workers:
The Cassandra Data
In part I we had 3 Cassandra nodes on which we created a table called posts. We saw that rows of this table are partitioned (or sharded) across the 3 nodes based on the primary key, which is the username. If the replication factor is 2, then each partition will have 2 copies (on separate nodes).
For this example I reused the same posts table but set a replication factor of 1. This can be updated by altering the keyspace:
cql> ALTER KEYSPACE posts_db WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 1 };
There is a nodetool command in Cassandra to find out which primary key will end up in which node:
nodetool getendpoints <keyspace> <table> <primary_key_value>
Then I used the following command to find 3 different usernames which will be sharded into separate nodes:
$ docker exec cass1 nodetool getendpoints posts_db posts 'lepellen' 192.168.0.201 $ docker exec cass1 nodetool getendpoints posts_db posts 'arnaud' 192.168.0.202 $ docker exec cass1 nodetool getendpoints posts_db posts 'nicolas' 192.168.0.203
And I inserted new posts for these 3 users:
$ docker run -it --rm cassandra cqlsh 192.168.0.201 cqlsh> USE posts_db; cqlsh> SELECT * FROM POSTS; username | creation | content ----------+--------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ arnaud | 341f1e50-a5bf-11e6-a21b-6d2c86545d91 | Miles Davis played the trumpet arnaud | 342eaeb0-a5bf-11e6-a21b-6d2c86545d91 | John Coltrane was a Saxophone virtuoso. arnaud | 34342cf0-a5bf-11e6-a21b-6d2c86545d91 | Charles Mingus was a great composer and bass player. arnaud | 3439ab30-a5bf-11e6-a21b-6d2c86545d91 | Pat Martino is a great jazz guitar player who lost his memory and had to re-learn how to play guitar all over again. nicolas | 398346a0-a5bf-11e6-a21b-6d2c86545d91 | This post was created in the webapp and stored in Cassandra ! nicolas | 398ff0d0-a5bf-11e6-a21b-6d2c86545d91 | Javascript has tons of cool frameworks and libraries: Node, Angular, Gulp, Webpack, and much more. nicolas | 399dfa90-a5bf-11e6-a21b-6d2c86545d91 | Python has the best syntax ! It looks clean and simple. And it is easy to understand for non-programmers. nicolas | 39aa56a0-a5bf-11e6-a21b-6d2c86545d91 | Java, Scala and Groovy are compiled to Java-Bytecode, which is the instruction set of the Java Virtual Machine. This bytecode and can be run on any kind of platform which has JRE installed ! nicolas | 61f60af0-a5bf-11e6-a21b-6d2c86545d91 | PHP is lame ! I don't want to talk about it... But my blog is run by PHP :( nicolas | 681ee2d0-a5bf-11e6-a21b-6d2c86545d91 | HTML and CSS are declarative languages. They describe what the end result must be, but not how to achieve that goal. lepellen | 30621650-a5bf-11e6-a21b-6d2c86545d91 | Paris is a nice city with lots of cultural stuff to do and lots of wine to drink lepellen | 306fd1f0-a5bf-11e6-a21b-6d2c86545d91 | Singapore is really clean, but it is too small. lepellen | 313bd480-a5bf-11e6-a21b-6d2c86545d91 | Tokyo is great ! (13 rows)
So the data is composed of posts:
- By lepellen, about travelling, stored in the cass1 container on ubuntu1 machine.
- By arnaud, about jazz music, stored in the cass2 container on ubuntu2 machine.
- By nicolas, about programming, stored in the cass3 container on ubuntu3 machine.
In the next section we will use this data to see if the deployed workers take advantage of data locality.
Using the Cassandra Connector
First let’s run a spark shell (Scala) in the master container:
dock@ubuntu0:~$ docker exec -ti sparkmaster bash root@ubuntu0:/app# ./spark/bin/spark-shell \ --master spark://ubuntu0:7077 \ --packages datastax:spark-cassandra-connector:2.0.0-M2-s_2.11 \ --conf spark.cassandra.connection.host=ubuntu1
There are 3 options:
- –master : This time we specify the master url to use it in standalone mode with all its workers.
- –packages : This downloads a given library (in this case the Datastax Cassandra connector) from https://spark-packages.org/ as well as its dependencies.
- –conf : We specify a Cassandra node in a property which will be used by the connector to auto-discover all other nodes.
The startup output show that the connector library is downloaded from spark-packages, and then Apache Ivy takes care of downloading all its dependencies from the Maven central repository:
Ivy Default Cache set to: /root/.ivy2/cache
The jars for the packages stored in: /root/.ivy2/jars
:: loading settings :: url = jar:file:/app/spark/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
datastax#spark-cassandra-connector added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent;1.0
confs: [default]
found datastax#spark-cassandra-connector;2.0.0-M2-s_2.10 in spark-packages
found com.twitter#jsr166e;1.1.0 in central
found org.joda#joda-convert;1.2 in central
found io.netty#netty-all;4.0.33.Final in central
found commons-beanutils#commons-beanutils;1.8.0 in central
found joda-time#joda-time;2.3 in central
found org.scala-lang#scala-reflect;2.10.6 in central
downloading http://dl.bintray.com/spark-packages/maven/datastax/spark-cassandra-connector/2.0.0-M2-s_2.10/spark-cassandra-connector-2.0.0-M2-s_2.10.jar ...
[SUCCESSFUL ] datastax#spark-cassandra-connector;2.0.0-M2-s_2.10!spark-cassandra-connector.jar (4563ms)
downloading https://repo1.maven.org/maven2/com/twitter/jsr166e/1.1.0/jsr166e-1.1.0.jar ...
[SUCCESSFUL ] com.twitter#jsr166e;1.1.0!jsr166e.jar (338ms)
downloading https://repo1.maven.org/maven2/org/joda/joda-convert/1.2/joda-convert-1.2.jar ...
[SUCCESSFUL ] org.joda#joda-convert;1.2!joda-convert.jar (283ms)
downloading https://repo1.maven.org/maven2/io/netty/netty-all/4.0.33.Final/netty-all-4.0.33.Final.jar ...
[SUCCESSFUL ] io.netty#netty-all;4.0.33.Final!netty-all.jar (1282ms)
downloading https://repo1.maven.org/maven2/commons-beanutils/commons-beanutils/1.8.0/commons-beanutils-1.8.0.jar ...
[SUCCESSFUL ] commons-beanutils#commons-beanutils;1.8.0!commons-beanutils.jar (732ms)
downloading https://repo1.maven.org/maven2/joda-time/joda-time/2.3/joda-time-2.3.jar ...
[SUCCESSFUL ] joda-time#joda-time;2.3!joda-time.jar (412ms)
downloading https://repo1.maven.org/maven2/org/scala-lang/scala-reflect/2.10.6/scala-reflect-2.10.6.jar ...
[SUCCESSFUL ] org.scala-lang#scala-reflect;2.10.6!scala-reflect.jar (848ms)
:: resolution report :: resolve 21822ms :: artifacts dl 8523ms
:: modules in use:
com.twitter#jsr166e;1.1.0 from central in [default]
commons-beanutils#commons-beanutils;1.8.0 from central in [default]
datastax#spark-cassandra-connector;2.0.0-M2-s_2.10 from spark-packages in [default]
io.netty#netty-all;4.0.33.Final from central in [default]
joda-time#joda-time;2.3 from central in [default]
org.joda#joda-convert;1.2 from central in [default]
org.scala-lang#scala-reflect;2.10.6 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 7 | 7 | 7 | 0 || 7 | 7 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent
confs: [default]
7 artifacts copied, 0 already retrieved (11944kB/180ms)
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/11/05 16:58:57 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/05 16:59:02 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.0.200:4040
Spark context available as 'sc' (master = local[*], app id = local-1478365141161).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_111)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
We can then use the input format provided by the connector to load the table into a distributed DataFrame:
scala> :paste
val posts = spark.read.format("org.apache.spark.sql.cassandra")
.options(Map( "table" -> "posts", "keyspace" -> "posts_db"))
.load()
Now we can perform distributed computing tasks such as a Word Count. But let’s do something more interesting and create an inverted index which maps each word in all posts to the IP-address of the worker which processed it:
scala> :paste
import java.net.InetAddress
val counts = posts.rdd
.flatMap(line => line.getString(2).replaceAll("""[^a-zA-Z]""", " ").split(" "))
.map(word => (word, Set(InetAddress.getLocalHost.getHostAddress)))
.reduceByKey(_ ++ _)
.sortByKey()
.collect()
counts.foreach{ t => println(t._1 + (" " * (15-t._1.length)) + " => " + t._2) }
Below are the results of this job. If you compare the mapping with the data described in the previous section, you can see that each worker processed the data from the Cassandra node of the same host. The connector did its job well !
=> Set(192.168.0.201, 192.168.0.203) And => Set(192.168.0.203) Angular => Set(192.168.0.203) But => Set(192.168.0.203) Bytecode => Set(192.168.0.203) CSS => Set(192.168.0.203) Cassandra => Set(192.168.0.203) Charles => Set(192.168.0.202) Coltrane => Set(192.168.0.202) Davis => Set(192.168.0.202) Groovy => Set(192.168.0.203) Gulp => Set(192.168.0.203) HTML => Set(192.168.0.203) I => Set(192.168.0.203) It => Set(192.168.0.203) JRE => Set(192.168.0.203) Java => Set(192.168.0.203) Javascript => Set(192.168.0.203) John => Set(192.168.0.202) Machine => Set(192.168.0.203) Martino => Set(192.168.0.202) Miles => Set(192.168.0.202) Mingus => Set(192.168.0.202) Node => Set(192.168.0.203) PHP => Set(192.168.0.203) Paris => Set(192.168.0.201) Pat => Set(192.168.0.202) Python => Set(192.168.0.203) Saxophone => Set(192.168.0.202) Scala => Set(192.168.0.203) Singapore => Set(192.168.0.201) They => Set(192.168.0.203) This => Set(192.168.0.203) Tokyo => Set(192.168.0.201) Virtual => Set(192.168.0.203) Webpack => Set(192.168.0.203) a => Set(192.168.0.202, 192.168.0.201) about => Set(192.168.0.203) achieve => Set(192.168.0.203) again => Set(192.168.0.202) all => Set(192.168.0.202) and => Set(192.168.0.201, 192.168.0.203, 192.168.0.202) any => Set(192.168.0.203) are => Set(192.168.0.203) bass => Set(192.168.0.202) be => Set(192.168.0.203) best => Set(192.168.0.203) blog => Set(192.168.0.203) but => Set(192.168.0.201, 192.168.0.203) by => Set(192.168.0.203) bytecode => Set(192.168.0.203) can => Set(192.168.0.203) city => Set(192.168.0.201) clean => Set(192.168.0.203, 192.168.0.201) compiled => Set(192.168.0.203) composer => Set(192.168.0.202) cool => Set(192.168.0.203) created => Set(192.168.0.203) cultural => Set(192.168.0.201) declarative => Set(192.168.0.203) describe => Set(192.168.0.203) do => Set(192.168.0.201) don => Set(192.168.0.203) drink => Set(192.168.0.201) easy => Set(192.168.0.203) end => Set(192.168.0.203) for => Set(192.168.0.203) frameworks => Set(192.168.0.203) goal => Set(192.168.0.203) great => Set(192.168.0.202, 192.168.0.201) guitar => Set(192.168.0.202) had => Set(192.168.0.202) has => Set(192.168.0.203) his => Set(192.168.0.202) how => Set(192.168.0.202, 192.168.0.203) in => Set(192.168.0.203) installed => Set(192.168.0.203) instruction => Set(192.168.0.203) is => Set(192.168.0.203, 192.168.0.202, 192.168.0.201) it => Set(192.168.0.203, 192.168.0.201) jazz => Set(192.168.0.202) kind => Set(192.168.0.203) lame => Set(192.168.0.203) languages => Set(192.168.0.203) learn => Set(192.168.0.202) libraries => Set(192.168.0.203) looks => Set(192.168.0.203) lost => Set(192.168.0.202) lots => Set(192.168.0.201) memory => Set(192.168.0.202) more => Set(192.168.0.203) much => Set(192.168.0.203) must => Set(192.168.0.203) my => Set(192.168.0.203) nice => Set(192.168.0.201) non => Set(192.168.0.203) not => Set(192.168.0.203) of => Set(192.168.0.201, 192.168.0.203) on => Set(192.168.0.203) over => Set(192.168.0.202) platform => Set(192.168.0.203) play => Set(192.168.0.202) played => Set(192.168.0.202) player => Set(192.168.0.202) post => Set(192.168.0.203) programmers => Set(192.168.0.203) re => Set(192.168.0.202) really => Set(192.168.0.201) result => Set(192.168.0.203) run => Set(192.168.0.203) set => Set(192.168.0.203) simple => Set(192.168.0.203) small => Set(192.168.0.201) stored => Set(192.168.0.203) stuff => Set(192.168.0.201) syntax => Set(192.168.0.203) t => Set(192.168.0.203) talk => Set(192.168.0.203) that => Set(192.168.0.203) the => Set(192.168.0.202, 192.168.0.203) to => Set(192.168.0.203, 192.168.0.202, 192.168.0.201) tons => Set(192.168.0.203) too => Set(192.168.0.201) trumpet => Set(192.168.0.202) understand => Set(192.168.0.203) virtuoso => Set(192.168.0.202) want => Set(192.168.0.203) was => Set(192.168.0.203, 192.168.0.202) webapp => Set(192.168.0.203) what => Set(192.168.0.203) which => Set(192.168.0.203) who => Set(192.168.0.202) wine => Set(192.168.0.201) with => Set(192.168.0.201)
Bonus: Using Python
The options are the same when starting PySpark:
root@ubuntu0:/app# ./spark/bin/pyspark \ --master spark://ubuntu0:7077 \ --packages datastax:spark-cassandra-connector:2.0.0-M2-s_2.11 \ --conf spark.cassandra.connection.host=ubuntu1
Loading the table looks like this:
>>> posts = spark.read.format("org.apache.spark.sql.cassandra").options(table="posts", keyspace="posts_db").load()
And finally the index generation job looks like this:
>>> import re, socket
>>> result = posts.rdd \
.flatMap(lambda row: re.sub(r'[^a-zA-Z]+', ' ', row[2]).lower().split(' ')) \
.map(lambda word: (word, set([socket.gethostbyname(socket.gethostname())]))) \
.reduceByKey(lambda a,b : a.union(b)) \
.sortByKey() \
.collect()
>>> print("\n".join([entry[0] + ' ' * (15-len(entry[0])) + ' => ' + str(entry[1]) for entry in result]))
Conclusion
Using Spark we can query and process Cassandra data any way we want. Now that we have all the containers we need, let’s move on to the orchestration part and see how we can organize their deployment in a cluster.
These docs are magnificent. I understand the time and patience you had to write these.
Thanks! Very much appreciated!