Spark in a general cluster-computing framework, and in our case we will use it to process data from the Cassandra cluster. As we saw in Part I, we cannot run any type of query on a Cassandra table. But by running a Spark worker on each host running a Cassandra node, we can efficiently read/analyse all of its data in a distributed way. Each Spark worker (slave) will read the data from its local Cassandra node and send the result back to the Spark driver (master). 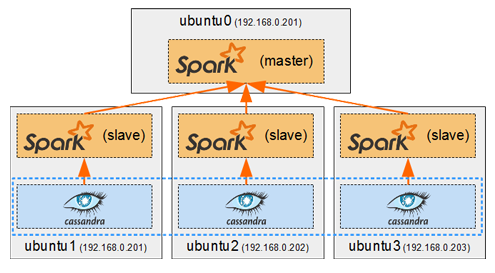
Tag: <span>Python</span>

Now that we have deployed containers to have a Cassandra cluster and a Replicated MySQL cluster, it’s time to create the web application which will make use of them. We will create Docker images a proxied Django/uWSGI/Nginx web app, which will connect to the MySQL cluster for OLTP data (django authentication, sessions, etc…), and to the Cassandra cluster for OLAP data (stored user posts).
![]() In the previous post we saw how to quickly get IPython up and running with PySpark.
In the previous post we saw how to quickly get IPython up and running with PySpark.
Now we will set up Zeppelin, which can run both Spark-Shell (in scala) and PySpark (in python) Spark jobs from its notebooks.
We will build, run and configure Zeppelin to run the same Spark jobs in Scala and Python, using the Zeppelin SQL interpreter and Matplotlib to visualize SparkSQL query results.
A comparison between Scala and Python speeds, and between Zeppelin and IPython will be made to conclude this post.
Here is an easy way of running PySpark on IPython notebook for data science and visualization.
There are methods on the web which consist in creating an IPython profile or kernel in which PySpark must be started with other necessary jars. These methods can seem a bit complicated, and not suitable for all versions of IPython, especially for the newest versions where the profiles are deprecated because they were merged into the Jupyter configs.
So this is a simple way to run PySpark with a basic default IPython configuration, in 10 minutes, for any version of IPython later than 1.0.0.
![]()
We will use the Anaconda python distribution, because it can quickly install IPython and all the necessary scientific and data analysis tools by running a single installation script.