Spark in a general cluster-computing framework, and in our case we will use it to process data from the Cassandra cluster. As we saw in Part I, we cannot run any type of query on a Cassandra table. But by running a Spark worker on each host running a Cassandra node, we can efficiently read/analyse all of its data in a distributed way. Each Spark worker (slave) will read the data from its local Cassandra node and send the result back to the Spark driver (master). 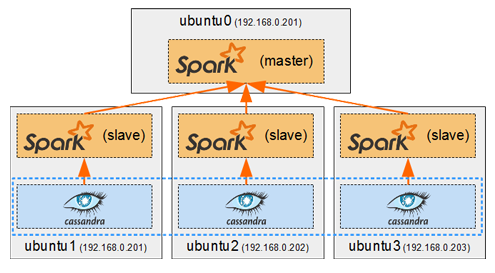
Tag: <span>Spark</span>
 In my previous series of posts, I’ve focused on using distributed computing frameworks, Hadoop and Spark, which had to be manually installed on Ubuntu on my cluster nodes.
In my previous series of posts, I’ve focused on using distributed computing frameworks, Hadoop and Spark, which had to be manually installed on Ubuntu on my cluster nodes.
In this series of posts I will write about how to use Docker to achieve automated distribution-independent deployment of any type of services on my cluster.
![]() In the previous post we saw how to quickly get IPython up and running with PySpark.
In the previous post we saw how to quickly get IPython up and running with PySpark.
Now we will set up Zeppelin, which can run both Spark-Shell (in scala) and PySpark (in python) Spark jobs from its notebooks.
We will build, run and configure Zeppelin to run the same Spark jobs in Scala and Python, using the Zeppelin SQL interpreter and Matplotlib to visualize SparkSQL query results.
A comparison between Scala and Python speeds, and between Zeppelin and IPython will be made to conclude this post.
Here is an easy way of running PySpark on IPython notebook for data science and visualization.
There are methods on the web which consist in creating an IPython profile or kernel in which PySpark must be started with other necessary jars. These methods can seem a bit complicated, and not suitable for all versions of IPython, especially for the newest versions where the profiles are deprecated because they were merged into the Jupyter configs.
So this is a simple way to run PySpark with a basic default IPython configuration, in 10 minutes, for any version of IPython later than 1.0.0.
![]()
We will use the Anaconda python distribution, because it can quickly install IPython and all the necessary scientific and data analysis tools by running a single installation script.
 In this part, we will run a simple Word Count application on the cluster using Hadoop and Spark on various platforms and cluster sizes.
In this part, we will run a simple Word Count application on the cluster using Hadoop and Spark on various platforms and cluster sizes.
We will run and benchmark the same program on 5 datasets of different sizes on :
- A single MinnowBoard MAX, using a multi-threaded simple java application
- A real home computer (my laptop), using the same simple java application
- MapReduce, using a cluster of 2 to 4 slaves
- Spark, using a cluster of 2 to 4 slaves
Using these results we will hopefully be able to answer to the original questions of this section : is a home cluster with such small computers worth it ? How many nodes does it take to be faster than a single node, or faster than a real computer ?

In this part, we will see how to install and configure Hadoop (2.7.1) and Spark (1.5.1) to have one master and four slaves.
The configurations in this part are adapted for MinnowBoard SBCs. I tried to give as much explanations on the chosen values, which are relative to the resources of this specific cluster. If you have any questions, or if you doubt my configuration, feel free to comment. 🙂
We start by creating a user which we will use for all Hadoop related tasks. Then we will see how to install and configure the master and slaves. Finally we will finish by running a simple MapReduce job to check that everything works and to start being familiar with the Hadoop ecosystem.