![]() In the previous post we saw how to quickly get IPython up and running with PySpark.
In the previous post we saw how to quickly get IPython up and running with PySpark.
Now we will set up Zeppelin, which can run both Spark-Shell (in scala) and PySpark (in python) Spark jobs from its notebooks.
We will build, run and configure Zeppelin to run the same Spark jobs in Scala and Python, using the Zeppelin SQL interpreter and Matplotlib to visualize SparkSQL query results.
A comparison between Scala and Python speeds, and between Zeppelin and IPython will be made to conclude this post.
Contents
Building Zeppelin
Zeppelin is still in a young stage of development and does not offer pre-compiled binaries, so we need to build it ourselves !
The version I use here is 0.6.0-SNAPSHOT, a snapshot from a couple of days before this post.
Installing the required tools (for Ubuntu)
To do so, make sure to have the following packages installed :
$ sudo apt-get install git $ sudo apt-get install libfontconfig $ sudo apt-get install npm $ sudo npm install -g bower # Check if bower works $ bower --version # Didn’t work for me, I had to fix compatibility problem by creating a symlink $ sudo ln -s /usr/bin/nodejs /usr/bin/nodell
We also need Maven, but a version greater than 3.1.1 is required, whereas the latest published version on APT is only 3.0.4 !
Here is how I installed the latest version of Maven (3.3.3), only for my Hadoop and Spark user called “hduser”, without modifying the system-wide APT-installed maven :
# Download from desired mirror at https://maven.apache.org/download.cgi wget "http://www.eu.apache.org/dist/maven/maven-3/3.3.3/binaries/apache-maven-3.3.3-bin.tar.gz" # Create directory in /usr/local/ and extract the archive there sudo mkdir -p /usr/local/apache-maven sudo tar -xzf apache-maven-3.3.3-bin.tar.gz -C /usr/local/apache-maven
Then, for users who want to use this version of Maven, modify the ~/.profile to add this at the end :
export M2_HOME=/usr/local/apache-maven/apache-maven-3.3.3 export M2=$M2_HOME/bin export MAVEN_OPTS="-Xms256m -Xmx512m" export PATH=$M2:$PATH
Then logout and re-login. This will use the “new” maven for this user, even if you already has a maven APT package previously installed.
Maven Build
The Zeppelin source code is available at https://github.com/apache/incubator-zeppelin/. You can either download the code as a zip file from there, or clone the repository by running :
$ git clone "https://github.com/apache/incubator-zeppelin/"
Then go into the root folder (after renaming it to a more simple name, if you want to) and start the maven build :
$ mv incubator-zeppelin/ zeppelin $ cd zeppelin $ mvn clean package -Pspark-1.5 -Dspark.version=1.5.1 -Dhadoop.version=2.7.1 -Phadoop-2.6 -Pyarn -Ppyspark -DskipTests
Remarks on the maven package command :
- Specify -Pyarn to be able to use spark on YARN
- Specify -Ppyspark to be able to run PySpark, or any Python code at all !
- Notice that -Phadoop is 2.6 whereas my version of Hadoop is 2.7.1. If you read the GitHub repo readme file, they use 2.6 for this parameter, even with Hadoop 2.7.0. I tried changing this to 2.7 but it prints a warning at the end of the build saying that the version was not recognized. So you’d better stick to 2.6 for the time being.
Configuration
Shell configuration file
After the build has finished (which took more than half an hour for me), create the bash configuration file using the provided template :
$ cp conf/zeppelin-env.sh.template conf/zeppelin-env.sh
And add the following lines :
export ZEPPELIN_PORT=9080 export ZEPPELIN_NOTEBOOK_DIR=/home/hduser/notebooks_zeppelin export SPARK_HOME=/home/hduser/spark export HADOOP_CONF_DIR=/home/hduser/hadoop/etc/hadoop
Zeppelin uses 2 successive ports, for HTTP and WebSocket respectively, which are by default 8080 and 8081. However these two ports are also default port values used by Spark in Standalone mode, so I changed the Zeppelin port to 9080 (which means 9081 for WebSocket) to avoid conflicts.
The ZEPPELIN_NOTEBOOK_DIR determines in which directory notebooks should be stored. The last two variables are simply Spark and Hadoop home and configuration paths.
In-App Interpreter configuration
First, start the Zeppelin daemon :
$ zeppelin/bin/zeppelin-daemon.sh start
Then after a few seconds, open http://{master_host}:9080 in your browser. You should see the Welcome page. Click on the “Interpreter” button on the top menu bar and you should arrive to this page :

Local Spark Configuration
By default, the master property is set to local[*] , which runs a local Spark with as many executors as local CPU cores.
YARN mode configuration
The screenshot above is the configuration to run Spark on top of YARN on my mini-cluster.
The master property must be set to yarn-client .
By default, YARN only creates 2 executors, so I added the spark.executor.instances property to the list, by clicking on the “edit” button on the upper right corner of the interpreter box, and setting its value to 4.
Standalone mode configuration
For standalone mode, simply set the master property to spark://{master_host}:7077.
Example in Python
Below is an example notebook, running the WordCount job that I used in my cluster benchmarks, and also in the previous post using IPython notebook.
This example uses both Matplotlib and the zeppelin SQL visualization module to view SparkSQL results :
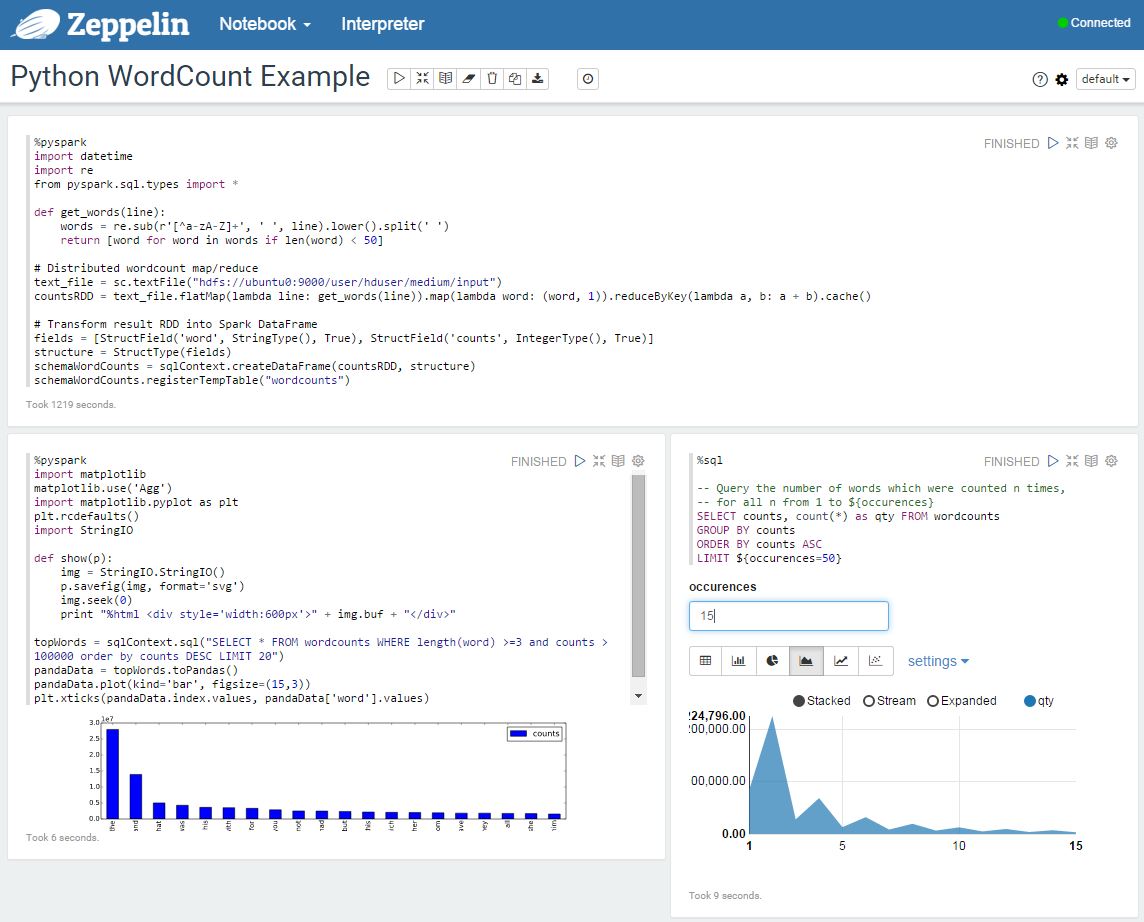
Using the PySpark and SQL Interpreters
To use python and/or PySpark in Zeppelin, use the %pyspark interpreter.
To use the SQL interpreter, type %sql before the SQL query you want to visualize.
Plotting with matplotlib
Unlike IPython, Zeppelin does not natively support displaying Matplotlib plots, but using a small hack we can write the plot image data into a StringIO and display the image data in HTML.
Here is the code you should use to make it work :
%pyspark
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
plt.rcdefaults()
import StringIO
def show(p):
img = StringIO.StringIO()
p.savefig(img, format='svg')
img.seek(0)
print "%html <div style='width:600px'>" + img.buf + "</div>"
""" Prepare your plot here ... """
# Use the custom show function instead of plt.show()
show(plt)
This code first tells matplotlib to use the “Agg” mode to write images and not to interactively try and open an window to display the plot. Otherwise, this will create an error if you don’t have an X-Server to remotely open X windows.
Warning : Be sure to call matplotlib.use(‘Agg’) before importing pyplot, otherwise it won’t be taken into account, and you’ll need to restart the interpreter to make it work again using the correct order.
Example in Scala
Here is the same example in Scala, using the Zeppelin SQL interpreter and visualization for two different queries :
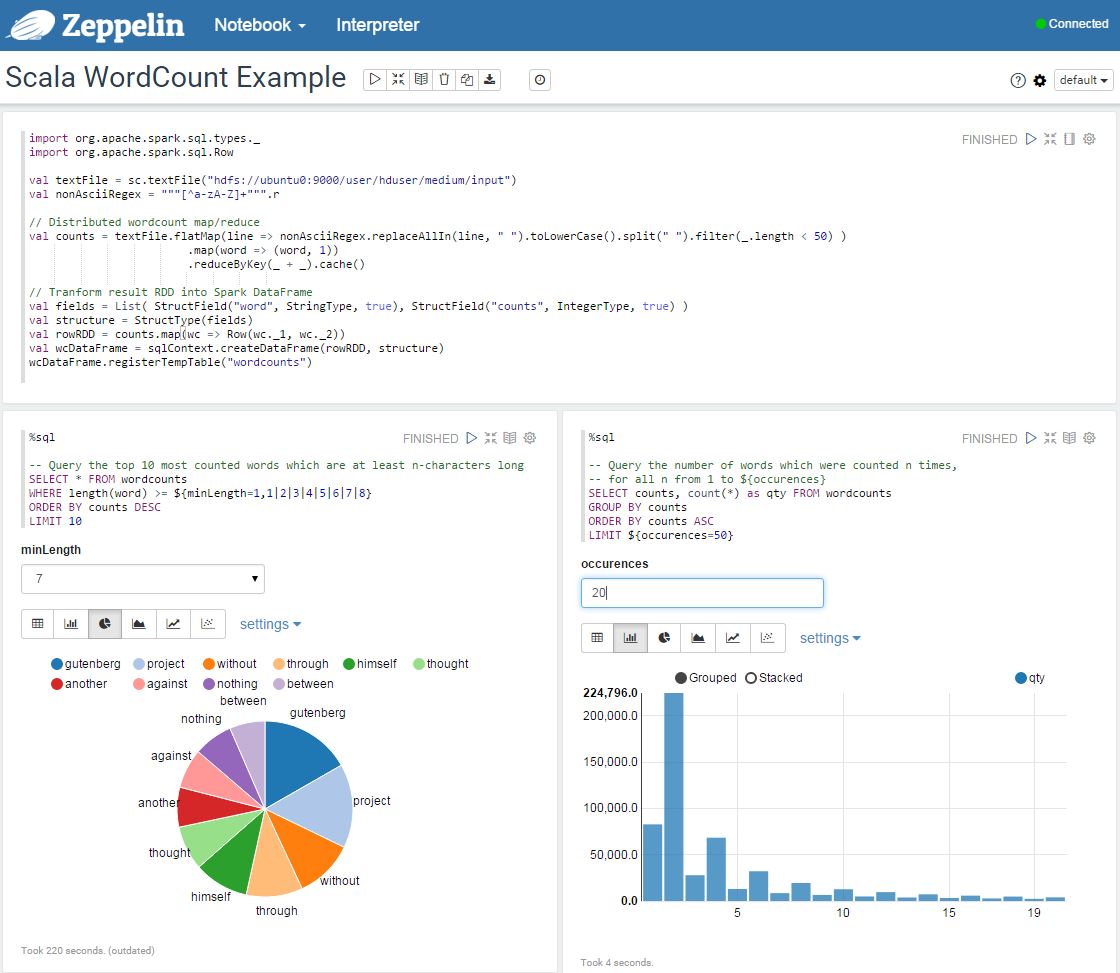
Conclusion
Scala vs Python
Using my home-cluster in Spark Standalone mode, running the same Word Count job in Python and Scala, the times I got for doing the Map/Reduce task, transforming the result to a DataFrame and executing the first SparkSQL query are :
- Python : ~20.4 minutes
- Scala : ~3.6 minutes
This should only include very little Zeppelin overhead, having previously run tasks to warm up the interpreters.
The Python time is about the same as using IPython, as seen in my previous post.
The Scala time is even faster than when submitting a Java job (non-interactive Spark) which took a bit more than 5 minutes, as seen in my cluster benchmark. This is because when using the interactive spark shells, the executors are already initialized and ready to work before submitting the tasks, so there is no wasted initialization time like when submitting a job in Java.
Zeppelin vs IPython
Here is a small list of Zeppelin pros and cons that I noticed, compared to IPython :
Pros :
- Progress bar, which is quite accurate when running Spark jobs.
- Nice SQL interactive plotting function.
- Splittable paragraph blocks for nicer viewing.
- Supports both Python and Scala.
- In-app graphical configuration to switch Spark modes and properties.
Cons :
- Very slow to start interpreters (often more than a minute !)
- Needs a hack for Matplotlib. It would be nice if it could be as easy as in IPython.
- In Scala it automatically outputs all variables, it’s quite annoying and cannot be configured.
Zeppelin still has some weaknesses, but it’s still a young project and should get better with time. It’s clearly Spark-oriented so I think it’s a good idea to stick with for someone working with Spark exclusively.
Hi, thank you fro the nice post, I have a question regarding the default plotting of Zeppelin when we use z.show() on a data frame.
Zeppelin limits the display of the results to 1000, I know that we can change this number but when I change it to a hight number Zeppelin becomes slow. And the default plotting tool of Zeppelin also plot only first 1000 results.
Is there a configuration or a way to make the plotting tool plot all the data and not only the limited results?
Hi !
I think that plotting ALL of your dataframe data is a bad idea in general because :
– All the data of your distributed DataFrame may not fit into your driver’s memory
– If it does fit, it will probably crash your browser, because Zeppelin plots are interactive and javascript-based. For me the histogram graph crashes Chrome browser above 2500 results.
– You can’t visualize anything having that much results. For example with the Pie Chart view, having 200 results, the legend will cover the whole space and your pie chart will be pushed down out of the screen.
I think that for all these reasons Zeppelin decided to limit the results of z.show().
If you are using Python, you can use matplotlib to plot everything in a single graph, it won’t explode your browser because there is no javascript… But maybe it will explode in your server side process while keeping thousands/millions of graphical objects in memory.
If you are using Scala I don’t think you can use a plotting library to generate an image like matplotlib in Zeppelin .. The best I know is to print each result manually :
dataFrame.collect().foreach { println }Now, if you REALLY want to try and plot EVERYTHING in zeppelin plotting tool, here is what I found out searching in the Zeppelin source code, in the following classes (paths relative to the zeppelin project root) :
– spark/src/main/java/org/apache/zeppelin/spark/ZeppelinContext.java
– spark/src/main/resources/python/zeppelin_pyspark.py
From the java class, for example, you can search “show” and see that z.show(dataFrame) actually calls a method called “showDF” in your case, which in turns calls dataFrame.take(maxResults). The parameter in dataFrame.take() is the number of results to be returned, and by default in SparkSQL it seems to be 20, but Zeppelin decides to pass it the maxResults value from your interpreter configuration.
Here is the line of code which seems to pass the maxResults parameter to SparkSQL’s DataFrame (at line 300 of ZeppelinContext.java in my recent master version of the Zeppelin repo) :
rows = (Object[]) take.invoke(df, maxResult + 1);So removing the maxResults parameter in this class won’t work, because it will use 20 as SparkSQL’s own default value. But you can maybe call the “collect” method of DataFrame (which takes everything), instead of “take”. Then you must rebuild Zeppelin.
I haven’t tried this because it takes time to build and test, and I think the plotting is limited by the front-end javascript side anyways.
Good luck !
Hi Nicolas, thank you for the detailed excellent explanation!
I was hoping to show all the data and then play with the keys, groups and values to slice and dice the data directly. I think that I have to do the grouping first in SparkSQL or with the data frame then show the grouped data rather than all of it 🙂
Thank you very much again
Rami