Now that we have a Sequence File containing our newly “structured” data, let’s see how can get the results to a basic query using MapReduce.
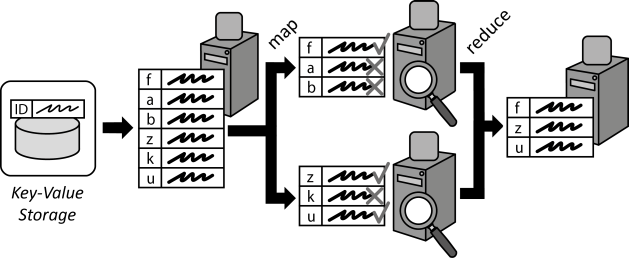 We will illustrate how filtering, aggregation and simple sorting can be achieved in MapReduce. For beginners, these are fundamental operations that can help you understand the MapReduce framework. Advanced readers can still read it quickly to get familiar with the dataset and get ready for the next posts which will be about more advanced sorting and joining techniques.
We will illustrate how filtering, aggregation and simple sorting can be achieved in MapReduce. For beginners, these are fundamental operations that can help you understand the MapReduce framework. Advanced readers can still read it quickly to get familiar with the dataset and get ready for the next posts which will be about more advanced sorting and joining techniques.
Contents
The Query
Let’s say we want to :
“View all donor cities by descending order of donation total amount, considering only donations which were not issued by a teacher. City names should be case insensitive (using upper-case)”
This could be formulated in SQL as :
SELECT SUM(total) as sumtotal, UPPER(donor_city) as city FROM donations WHERE donor_is_teacher != 't' GROUP BY UPPER(donor_city) ORDER BY sumtotal DESC;
This query actually involves quite a few operations :
- Filtering on the value of donor_is_teacher
- Aggregating the sum of total values grouping by city
- Sorting on the aggregated value sumtotal
The MapReduce solution
This task could be broken down into 2 MapReduce jobs :
- First Job : Filtering and Aggregation
- Map
- Input : DonationWritables “full row” objects from the SequenceFile.
- Output : (city, total) pairs for each entry only if donor_is_teacher is not true.
- Reduce
- Reduce by summing the “total” values for each “city” key.
- Map
- Second Job : Sorting
- Map
- Input : (city, sumtotal) pairs with summed total per city.
- Output : (sumtotal, city) inversed pair.
- Reduce
- Identity reducer. Does not reduce anything, but the shuffling will sort on keys for us.
- Map
Here is an illustration of the 2-job process we will implement, using a tiny sequence file example for the dataset :
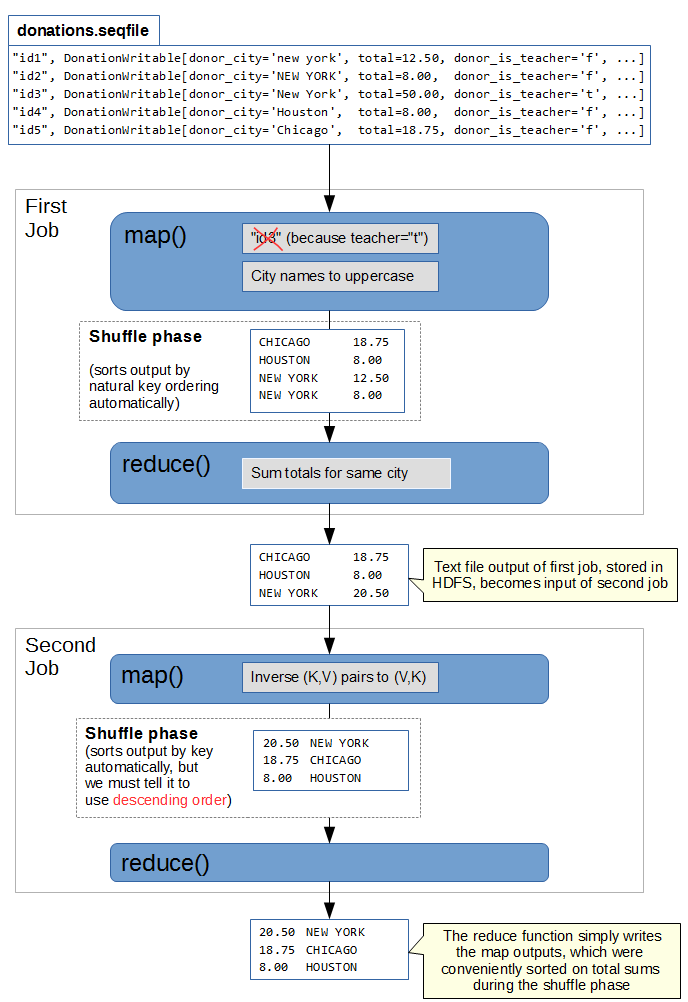
The First Job
Here is the code for this job : https://github.com/nicomak/[…]/DonationsSumByCity.java
This is a pretty straightforward and standard Map/Reduce job. It’s similar to the Word Count example given by Apache in their MapReduce tutorial.
Sequence File input format
A couple of things to notice here regarding the Sequence File as the input :
- job.setInputFormatClass(SequenceFileInputFormat.class)
- Tell the job that we are reading a Sequence File.
- … extends Mapper<Text, DonationWritable, Text, FloatWritable>
- The first two generic type parameters of the Mapper class should be the input Key and Value types of Sequence File.
- map(Text key, DonationWritable donation, Context context)
- The parameter of the map method are directly the Writable objects. If we were using the CSV input we would have a Text object as the second parameter containing the csv line, which we would have to split on commas to obtain values.
Using a Combiner
Since we are doing an aggregation task here, using our Reducer as a Combiner by calling job.setCombinerClass(FloatSumReducer.class) improves performance. It will start reducing the Mapper’s output during the map phase, which will result in less data being shuffled and sent to the Reducer.
The Second Job
Here is my code for this job : https://github.com/nicomak/[…]/OrderBySumDesc.java
This second job will take the output of the first job and sorts on the aggregated sums. The mapper simply inverses the input (city, sumtotal) pairs into output (sumtotal, city) pairs.
Then we simply use the basic default Reducer class and let MapReduce do the sorting on “sumtotal” for us.
In the next paragraphs we will refer to the mappers outputs (sumtotal, city) pairs as (K,V).
The Mapper
In this job the input file is a plain text file with <city, total> pairs on each line. The easiest way to deal with this is to use the KeyValueTextInputFormat and receive both key and value as Text objects in the Mapper. Then we convert each “total” value from Text to FloatWritable in the “map” method before inverting the key and the value. This is what I did to keep things simple.
However if you really want to receive <Text, FloatWritable> pairs directly as the mapper’s input, here are a couple of possibilities :
- In the first job write the output as a Sequence File of <Text,FloatWritable> pairs by defining SequenceFileOutputFormat as the output format class. Then this Second Job can directly read the key/value pairs from the Sequence File with correct types, using the SequenceFileInputFormat like in the first job.
- You can also write your own InputFormat implementation which can read <string,float> pairs from a plain text file. You will need to have a look at a couple of Hadoop classes, especially KeyValueTextInputFormat and its record reader KeyValueLineRecordReader, and modify their code to parse the value into a FloatWritable.
The default Reducer class
The Reducer class is used implicitly by MapReduce if no reducer class is specified, and if job.setNumReduceTasks(tasks) was not set to 0 (in which case there is no reduce phase). It is not necessary, but I still decided to set the reducer class and number of tasks explicitly in the driver code to be more clear.
In general, reduce operation receive an input in the form (K, list[V1,V2,…Vn]) containing a Key and all of its corresponding Values outputted from all Mappers. The reduce operation has to decide how to “reduce” it into a single pair (K,Vr) with a reduced value. This could be done by summing the values (as the first job did), multiplying them, appending them to a Set to find unique values, etc …
But the base Reducer does not really reduce values. Instead, it simply outputs all the values separately in (K,V1), (K,V2) … (K,Vn) pairs. In fact, if you don’t use any reducer, and set the number of tasks to 0, there would be no grouping of data. So you would end up with (K,V1), (K,V2), … (K,Vn) pairs as well, which are the outputs of your map method. So using the default Reducer or no reducer at all produces the same Key/Value pairs in the output. Which is why it is often called the “Identity Reducer”.
Using a Sort Comparator
So why bother using the default identity reducer ? Well we don’t actually need to reduce values here, but when using a reducer, MapReduce will automatically sort data on Keys between the map and reduce phases. So using a single Reducer task gives us 2 advantages :
- The reduce method will be called with increasing value of K, which will naturally result in (K,V) pairs ordered by increasing K in the output.
- Since we use only 1 reducer task, we will have all (K,V) pairs in a single output file, instead of the 4 mapper outputs.
- Even if we managed to sort the outputs from the mappers, the 4 outputs would be independently sorted on K, but the outputs wouldn’t be sorted between each other.
- Warning : if we use more than 1 reducers, the same problem will occur and we won’t be able to have a fully sorted result. More about this in the next post.
There is only one problem to handle now. In the first point above, I said that our map (K,V) pairs, which are in our case (sumtotal,city), would be sorted by increasing key. But our query said that we need to sort in decreasing order. Luckily, we can define our own comparator and tell it how to order the keys.
We create a WritableComparator which simply multiplies the “compareTo” value between 2 floats by -1, to have a descending order :
public static class DescendingFloatComparator extends WritableComparator {
public DescendingFloatComparator() {
super(FloatWritable.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
FloatWritable key1 = (FloatWritable) w1;
FloatWritable key2 = (FloatWritable) w2;
return -1 * key1.compareTo(key2);
}
}
We must specify this class as the Sort Comparator by calling job.setSortComparatorClass(DescendingFloatComparator.class).
Running and Viewing Results
Here are the terminal commands for executing and viewing the outputs for these 2 MapReduce jobs :
$ hadoop jar donors.jar mapreduce.donation.DonationsSumByCity donors/donations.seqfile donors/output_sumbycity $ hdfs dfs -cat donors/output_sumbycity/* [...] ROCKWALL 8422.99 ROCKWELL 80.0 ROCKWOOD 9224.17 [...] $ hadoop jar donors.jar mapreduce.donation.OrderBySumDesc donors/output_sumbycity donors/output_orderbysumdesc $ hdfs dfs -cat donors/output_orderbysumdesc/* | head 1.71921696E8 2.5504284E7 NEW YORK 1.5451513E7 SAN FRANCISCO 6163194.0 CHICAGO 5085116.5 SEATTLE 4453958.0 OKLAHOMA CITY 3383632.2 LOS ANGELES
As expected, the output of the first job is a plain text list of <city,sum> ordered by city name. The second job generates a list of <sum,city> sorted by descending sum.
Execution times :
- The first job took an average of 1 min 25 sec on my cluster.
- This second job took an average of 1 min 02 sec on my cluster.
In this query we did a simple sort on a single attribute. In the next posts we will explore more advanced sorting techniques to sort on multiple attributes and sort using multiple reducers.
Is it possible to aggregate the data as each key is processed? My problem is to count the records that fulfill some criteria were the key contains also a date among other characteristics. If my key has as the date part 01.01.2017 + 2 other characteristics I want it to calculate the sum of all previous dates which are the same on the other two characteristics.
Example of input:
Key: (01.01.2017 – A – B) , Value: 5
Key: (02.02.2017 – A – B), Value: 10
Key: (02.02.2017 – A – C), Value: 2
Key: (03.03.2017 – A – C), Value: 1
Final results should be:
01.01.2017 – A – B with value 5 (no other dates before this date)
02.02.2017 -A-B with value 15 (2nd recorded plus 1st record since both have same 2 characteristics A and B)
02.02.2017 – A – C with value 2 ( no other dates before with same characteristics)
03.02.2017 A – B with value 3 (3rd record plus 4th record since both have same 2 characteristics A and C)
Thanks in advance for any help.
make your A-B or A-C as well as date as as Key . sort it based on key as well as date . then in reducer write an create a variable and in the for loop itself write the output with accumulation and reset the accumulating variable when date changes.