We saw in the previous part that when using multiple reducers, each reducer receives (key,value) pairs assigned to them by the Partitioner. When a reducer receives those pairs they are sorted by key, so generally the output of a reducer is also sorted by key. However, the outputs of different reducers are not ordered between each other, so they cannot be concatenated or read sequentially in the correct order.
For example with 2 reducers, sorting on simple Text keys, you can have :
– Reducer 1 output : (a,5), (d,6), (w,5)
– Reducer 2 output : (b,2), (c,5), (e,7)
The keys are only sorted if you look at each output individually, but if you read one after the other, the ordering is broken.
The objective of Total Order Sorting is to have all outputs sorted across all reducers :
– Reducer 1 output : (a,5), (b,2), (c,5)
– Reducer 2 output : (d,6), (e,7), (w,5)
This way the outputs can be read/searched/concatenated sequentially as a single ordered output.
In this post we will first see how to create a manual total order sorting with a custom partitioner. Then we will learn to use Hadoop’s TotalOrderPartitioner to automatically create partitions on simple type keys. Finally we will see a more advanced technique to use our Secondary Sort’s Composite Key (from the previous post) with this partitioner to achieve “Total Secondary Sorting“.
Contents
Manual partitioning
In the previous part, our secondary sort job (view) used theNaturalKeyPartitioner to assign map output pairs to reducers based on the natural key (“state” field) hashcode.
One way to achieve total order sorting is to implement the getPartition() method of the Partitioner to manually assign keys by intervals to each reducer. For example, if we are going to use 3 reducers, we can try to have an equal distribution by partitioning keys this way :
- Reducer 0 : state names starting with A to I (includes 9 letters)
- Reducer 1 : state names starting with J to Q (includes 8 letters)
- Reducer 2 : state names starting with R to Z (includes 9 letters)
To do this, you can simply replace the NaturalKeyPartitioner by :
import org.apache.hadoop.mapreduce.Partitioner;
import data.writable.DonationWritable;
public class CustomPartitioner extends Partitioner<CompositeKey, DonationWritable> {
@Override
public int getPartition(CompositeKey key, DonationWritable value, int numPartitions) {
if (key.state.compareTo("J") < 0) {
return 0;
} else if (key.state.compareTo("R") < 0) {
return 1;
} else {
return 2;
}
}
}
Let’s execute this job again, using 3 reducers and our new custom partitioner :
$ hadoop jar donors.jar mapreduce.donation.secondarysort.OrderByCompositeKey donors/donations.seqfile donors/output_secondarysort $ hdfs dfs -ls -h donors/output_secondarysort Found 4 items -rw-r--r-- 2 hduser supergroup 0 2015-12-28 23:27 donors/output_secondarysort/_SUCCESS -rw-r--r-- 2 hduser supergroup 32.9 M 2015-12-28 23:27 donors/output_secondarysort/part-r-00000 -rw-r--r-- 2 hduser supergroup 29.8 M 2015-12-28 23:27 donors/output_secondarysort/part-r-00001 -rw-r--r-- 2 hduser supergroup 12.0 M 2015-12-28 23:27 donors/output_secondarysort/part-r-00002 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | head -n 3 c8e871528033bd9ce6b267ed8df27698 AA Canada 100.00 6eb5a716f73260c53a76a5d2aeaf3820 AA Canada 100.00 92db424b01676e462eff4c9361799c18 AA Canada 98.36 $ hdfs dfs -cat donors/output_secondarysort/part-r-00000 | tail -n 3 767e75dd5f7cb205b8f37a7a5ea68403 IN Zionsville 1.00 79f3e2549be8fea00ae65fed3143b8de IN Zionsville 1.00 adcd76454acb15743fa2761a8aebc7b9 IN zionsville 0.94 $ hdfs dfs -cat donors/output_secondarysort/part-r-00001 | head -n 3 a370876d2717ed9d52750b1199362e05 KS 11151 25.00 9b416f7760c0717c222130418c656eb9 KS 11151 25.00 f0c6dd10268c37fee0d5eeeafc81040c KS Abilene 100.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00001 | tail -n 3 bc214dd60705364cae4d5edb7b2fde96 PR TOA BAJA 25.00 aaa549ef89fe0a2668013a5c7f37ec55 PR Trujillo Alto 150.00 00da7cd5836b91d857ad1c62b4080a14 PR Trujillo Alto 15.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00002 | head -n 3 1fde8075005c72f2ca20bd5c1cb631a2 RI Adamsville 50.00 4a62f4e2de2ca06e8f84ca756992bcca RI Albion 50.00 1f3e940d0a2bbb56bc260a4c17ca3855 RI Albion 25.00 $ hdfs dfs -cat donors/output_secondarysort/part-r-00002 | tail -n 3 f0a9489e53a203e0f7f47e6a350bb19a WY Wilson 1.68 8aed3aba4473c0f9579927d0940c540f WY Worland 75.00 1a497106ff2e2038f41897248314e6c6 WY Worland 50.00
This yields a correct fully sorted 3-file result. If we look at the beginning and end of each output file, we can see that each state belongs to only one reducer. And we can also see a continuation in the ordering of states across all output files. This is a successful Total Order Sorting.
However, there are a couple of inconveniences using this technique :
- It was manually coded. If we want to use 4 reducers instead, we need to code a new partitioner.
- The load distribution is not equal between reducers. The first output file is nearly 3 times bigger than the last output file. We tried our best to divide the 26 letters of the alphabet, but the reality is that state names are not evenly distributed across the alphabet 🙁
To overcome these problems, there is a powerful but complicated partitioner in Hadoop called the TotalOrderPartitioner.
The TotalOrderPartitioner
Basically, the TotalOrderOrderPartitioner does the same thing as our custom class, but dynamically and with correct load balancing between reducers. To do that, it samples the input data to pre-calculate how to “separate” the input data into equal parts before the Map phase starts. It then uses those “separations” as partitioning boundaries during the mapper’s partitioning phase.
Simple Dataset for our Example
Let’s first create a more simple dataset to explain and test how the Total Order Partitioner works.
The GenerateListOfStateCity.java (view) MapReduce job will simply print out text pairs of (state,city) from the “donations” sequence file, in a random order :
$ hadoop jar donors.jar mapreduce.donation.secondarysort.totalorder.GenerateListOfStateCity donors/donations.seqfile donors/output_list_state_cities $ hdfs dfs -ls -h donors/output_list_state_cities Found 3 items -rw-r--r-- 2 hduser supergroup 0 2015-12-30 16:24 donors/output_list_state_cities/_SUCCESS -rw-r--r-- 2 hduser supergroup 9.3 M 2015-12-30 16:24 donors/output_list_state_cities/part-r-00000 -rw-r--r-- 2 hduser supergroup 9.3 M 2015-12-30 16:24 donors/output_list_state_cities/part-r-00001 $ hdfs dfs -cat donors/output_list_state_cities/part-r-00000 | head IL Chicago CA Canyon Country MN Sartell CA San Francisco TX Murchison TX Austin ID Blackfoot
TotalOrderPartitioner Workflow
Using the simple dataset we just generated, here is an illustration of how the TotalOrderPartitioner can help us sort the input by state across multiple reducers :
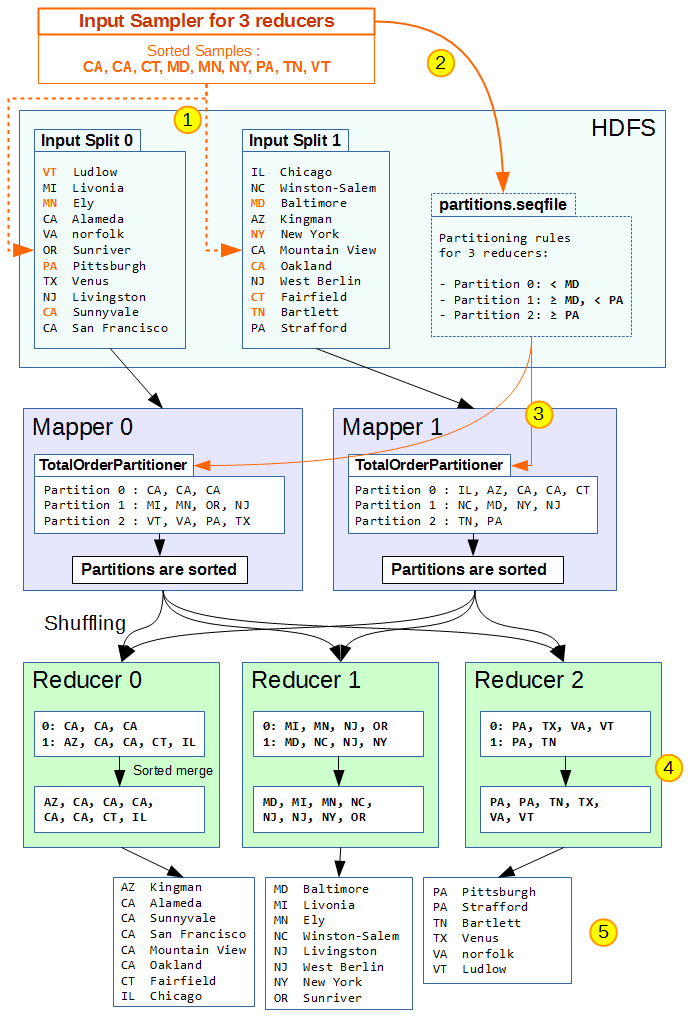
Here are some important details on what happens throughout the program :
- An InputSampler samples keys across all input splits, and sorts them using the job’s Sort Comparator. Different input sampler implementations are available in the Hadoop library :
- RandomSampler : samples randomly based on a given frequency. This is the one we use in this example.
- IntervalSampler : takes samples at regular intervals (for example every 5 records).
- SplitSampler : take the first n samples from each split.
- The input sampler writes a “partition file” Sequence File in HDFS, which delimits the different partition boundaries based on the sorted samples.
- For n reducers there are n-1 boundaries written to this file. In this example there are 3 reducers, so 2 boundaries are created : “MD” and “PA”.
- The MapReduce job begins with the mapper tasks. For partitioning, the mappers use the TotalOrderPartitioner, which will read the partition file from HDFS to obtain partition boundaries. Each map output is then stored in a partition based on these boundaries.
- After the shuffle, each reducer has fetched a sorted partition of (key,value) pairs from each mapper. At this point, all keys in reducer 2 are alphabetically greater than all keys in reducer 1, which are greater than all keys in reducer 0. Each reducer merges their sorted partitions (using a sorted merge-queue) and writes their output to HDFS.
Java Code for the Example
Here is the code, for this example job, which you can also view here on GitHub :
public class TotalOrderPartitionerExample {
public static void main(String[] args) throws Exception {
// Create job and parse CLI parameters
Job job = Job.getInstance(new Configuration(), "Total Order Sorting example");
job.setJarByClass(TotalOrderPartitionerExample.class);
Path inputPath = new Path(args[0]);
Path partitionOutputPath = new Path(args[1]);
Path outputPath = new Path(args[2]);
// The following instructions should be executed before writing the partition file
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, inputPath);
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), partitionOutputPath);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setMapOutputKeyClass(Text.class);
// Write partition file with random sampler
InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 1000, 100);
InputSampler.writePartitionFile(job, sampler);
// Use TotalOrderPartitioner and default identity mapper and reducer
job.setPartitionerClass(TotalOrderPartitioner.class);
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
This is a very simple job with a minimal use of the TotalOrderPartitioner. We don’t need to create specific Mapper and Reducer classes because we simply sort the input without changing any values or format. The default Mapper and Reducer classes will do. Some things to notice here :
- We use a RandomSampler with the following parameters :
- freq = 0.01 : The sampler will run through all records and each record will have a 0.01 (=1%) probability of being chosen as a sample.
- numSamples = 1000 : There will be a maximum of 1000 samples. If the maximum number of samples is reached, each new chosen record will replace an existing sample.
- maxSplitsSampled = 100 : Only 100 splits will be sampled. In our case there are only 2 splits so this maximum won’t be applied.
- The InputSampler.writePartitionFile() command is a blocking call. It will use the following configurations, which must to be specified beforehand :
- The job’s input paths : as inputs for the sampling.
- The number of reduce tasks : to write the “partition file” sequence file containing partition boundaries.
- The map output key class : to annoy us !! Well maybe i’m exaggerating a bit. More about this major plot point later on …
Execution and Analysis
$ hadoop jar donors.jar mapreduce.donation.totalorderpartitioner.TotalOrderPartitionerExample \
donors/output_list_state_cities \
donors/states_partitions.seqfile \
donors/output_totalorder_example
15/12/30 18:06:30 INFO input.FileInputFormat: Total input paths to process : 2
15/12/30 18:06:33 INFO partition.InputSampler: Using 1000 samples
...
$ hdfs dfs -cat donors/states_partitions.seqfile
SEQ♠↓org.apache.hadoop.io.Text!org.apache.hadoop.io.NullWritable *org.apache.hadoop.io.compress.DefaultCodec 99
Æ9ö
êB{2üZ}ö♥¬☻ ♂ ♥☻FLx9c♥ ♂ ♥☻NYx9c♥
$ hdfs dfs -ls -h donors/output_totalorder_example
Found 4 items
-rw-r--r-- 2 hduser supergroup 0 2015-12-30 18:07 donors/output_totalorder_example/_SUCCESS
-rw-r--r-- 2 hduser supergroup 5.3 M 2015-12-30 18:07 donors/output_totalorder_example/part-r-00000
-rw-r--r-- 2 hduser supergroup 7.0 M 2015-12-30 18:07 donors/output_totalorder_example/part-r-00001
-rw-r--r-- 2 hduser supergroup 6.4 M 2015-12-30 18:07 donors/output_totalorder_example/part-r-00002
$ hdfs dfs -cat donors/output_totalorder_example/part-r-00001 | head
FL Jacksonville
FL Clermont
FL Tampa
$ hdfs dfs -cat donors/output_totalorder_example/part-r-00001 | tail
NV Henderson
NV pahrump
NV Las Vegas
$ hdfs dfs -cat donors/output_totalorder_example/part-r-00002 | head
NY New York
NY New York
NY bronx
This time, when we execute the job, we have a log telling us how many samples will be taken.
The partition file which we specified, donors/states_partitions.seqfile, is not removed from HDFS after the job, so we can check out what’s inside. Well actually it’s compressed so it doesn’t look nice … But what we can see (or guess …) from top to bottom is :
- SEQ : start of the Sequence File header
- The <K,V> types, which are <Text,NullWritable>
- The compression codec class
- 2 things which look like US states ! Between some funny characters and unicode points we can identify “FL” and “NY”.
By visualizing outputs, we can see that the second outputs starts with FL state ! And the third output starts with NY.
The cities are not sorted, of course, because we have no control on how the values enter the reduce function, since we did not use Secondary Sort. But we succeeded in sorting by state across all reducers, and the output file are quite balanced in size, compared to our manual partitioning in the previous section. We can also change the number of reduce tasks in the job configuration from 3 to 4 or 10 without worrying about the partitioner.
Limitations and Annoyances
As said earlier in the example code remarks, the map output key class needs to be specified. And it must correspond to the Sampler<K,V> key class. If you try to remove the setMapOutputKeyClass(Text.class) command, or use it later after the call to InputSampler.writePartitionFile(), you will end up with this error :
Exception in thread "main" java.io.IOException: wrong key class: org.apache.hadoop.io.Text is not class org.apache.hadoop.io.LongWritable
at org.apache.hadoop.io.SequenceFile$RecordCompressWriter.append(SequenceFile.java:1383)
at org.apache.hadoop.mapreduce.lib.partition.InputSampler.writePartitionFile(InputSampler.java:340)
at mapreduce.donation.totalorderpartitioner.TotalOrderPartitionerExample.main(TotalOrderPartitionerExample.java:39)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
This raises a few questions :
- Why do we specify a V value class for the sampler ? It stored <Text, NullWritable> pairs in the partition file that we viewed, so apparently it doesn’t need to read values from the input.
- Probably because it was easier to implement, since everything is <K,V> parameterized in MapReduce. Especially for reading/writing Sequence Files.
- Why should I specify a map key class ? The Sampler’s generic types are already supposed to reflect the input types …
- I’m not really sure. I believe that it would be better if the types were independent. This is somewhat linked to the next question.
- Why is it a map OUTPUT key class ? The InputSampler reads input splits, which are the INPUTs to the mappers, not the OUTPUTs ! right ?
- This looks like a way to “encourage” us that we will use the same key types between the map input and output. This kinda makes sense, because sampling is done on the map input data, and partitioning is done on the map outputs. And the partitioner uses boundaries which are actually keys found during sampling, so they should be of the same type and same distribution.
To illustrate the logic of question 3 : take the example job we just ran. The partition file contains the boundaries “FL” and “NY”. Imagine we use a custom mapper which replaces (state,city) by (state.hashcode,city). So for example (‘IL’, ‘Chicago’) becomes (20918, ‘Chicago’), which is no longer of type <Text,Text>, but <IntWritable,Text>. How would you classify 20918 compared to “FL” and “NY” for partitioning ? That would make no sense and would surely break a type or cast error. With a less dramatic scenario, imagine your mapper doesn’t transform the input pairs, but discards all pairs where the state is smaller than “J”. There would be no error, but you would loose half of your records, and your first reducer would have absolutely no output, because it is supposed to sort states before “FL”.
From these observations we can assume that :
The InputSampler expects us to keep the same keys between the input and the output of the map function. This way the sampled data is guaranteed to reflect the map output data, by having the same data type and distribution.
Using a different input for sampling
The previous assumption is very reasonable. But sometimes we can’t use the same input data for sampling and partitioning.
Objective
The “donations” dataset we created in part I and used in part II is a Sequence File with types <Text, DonationWritable>. The keys are the unique IDs of each record. Let’s say we want to perform Total Order Sorting, to sort all records by state.
We can’t just use the InputSampler like we did in the previous section, because here the keys are IDs, and we need to sample some states if we need to partition on state name. But what we can do is :
- Use the file from the previous section, which contained all <state,city> pairs for sampling.
- In the mapper, transform the input (id,donation) to (state,donation) so that the output can be partitioned correctly using the partition file.
MapReduce Solution
I coded the solution to this problem in a class called TotalSortByState which you can view here on GitHub.
To make things clear, we create 2 jobs in the driver code : one for the sampling, and one for the actual MapReduce job.
- The samplingJob (verbose name “Sampling”) is dedicated to sampling its own input file.
- We call FileInputFormat.setInputPaths() and pass it the sampling file’s path.
- It uses a KeyValueTextInputFormat because its input file is a text file consisting of (state,city) pairs.
- We set its Map output key class to Text, because we have to, as explained in the previous section. The funny thing is, this job doesn’t even have a map phase. So this has become a simple formality.
- The mrJob (verbose name “Total Sorting MR Job”) is the real MapReduce job. It will sort data and use the TotalOrderParitioner, whose partition file was generated during the first job.
- We have to call FileInputFormat.setInputPaths() again and pass it the dataset’s file path.
- This time we use the SequenceFileInputFormat because the input file is a Sequence File.
Two values must obviously be shared between both jobs for this to work : the number of reducers, and the partition file destination. Otherwise the job will crash.
Execution and Analysis
$ hadoop jar donors.jar mapreduce.donation.totalorderpartitioner.TotalSortByState \ donors/donations.seqfile \ donors/output_list_state_cities \ donors/states_partitions.seqfile \ donors/output_totalsort_state $ hdfs dfs -ls -h donors/output_totalsort_state Found 4 items -rw-r--r-- 2 hduser supergroup 0 2016-01-02 12:04 donors/output_totalsort_state/_SUCCESS -rw-r--r-- 2 hduser supergroup 23.4 M 2016-01-02 12:04 donors/output_totalsort_state/part-r-00000 -rw-r--r-- 2 hduser supergroup 24.8 M 2016-01-02 12:04 donors/output_totalsort_state/part-r-00001 -rw-r--r-- 2 hduser supergroup 26.5 M 2016-01-02 12:04 donors/output_totalsort_state/part-r-00002 $ hdfs dfs -cat donors/output_totalsort_state/part-r-00001 | head d622ab566db407eae33a4bbcdcf5bf70 GA Atlanta 50.00 ccb49f74db096c1a87083fd6b455ff7c GA conyers 11.00 e8494363e9fb50de04aecc7fdd4bbb81 GA Savannah 25.00 $ hdfs dfs -cat donors/output_totalsort_state/part-r-00002 | head c8512e8ef3a3bed880d8e7b33ef7bbc4 NY New York 254.11 ff01eea5bafb60183e476781543bef5f NY Bronxville 487.01 ff01c078b68bf44ac75456be374d4af7 NY New York 145.00
We successfully used samples from the unordered “state-city” text file to partition our dataset on keys which were created in the map function.
We first said that the InputSampler wants us to keep the same keys between the input and the output of the map function to stay coherent between sampling and partitioning. This is what we did by using the default identity mapper in the previous section. This time we used a different file just for the InputSampler. But we still maintained coherence between the sampling and partitioning phases, because in the MR job we transformed our map input into an output which was the same data as the sampling file.
Total Secondary Sort by Composite Key
Now what if we want to do Total Order Sorting on our “donations” sequence file of <Text, DonationWritable> entries, using the same ordering as in the previous post ?
A first solution would be to use the same technique as in the previous section. We could create a sequence file of <CompositeKey, NullWritable> pairs for each record of our <Text, DonationWritable> sequence file, and then use it as a separate file for sampling. But it would be boring to do the same thing again. Luckily, I’ve found a workaround to do this directly on the dataset file.
Objective
We have the following contraints on our Total Order Sorting by Composite Key :
- We must maintain data type and coherence between the sampling and partitioning.
- The TotalOrderPartitioner uses the map output keys to calculate partitioning.
- Our map output keys are of type CompositeKey, because we are doing Secondary Sorting.
For these premises we can deduce that … we have no choice but to sample CompositeKeys ! It looks like the only way this is going to work.
But how ? Our InputSampler takes the “donors” sequence file as input, which is of type <Text, DonationWritable>, doesn’t it ? Well no, it doesn’t ! It takes the InputFormat as input. Muhahhaha ! We can do a small hack by modifying the InputFormat to extract and return CompositeKey keys on the fly instead of Text keys.
In fact, our custom InputFormat will use a custom RecordReader, which will randomly read DonationWritable objects from the sequence file, and extract CompositeKey objects from them.
Here is a little illustration of what we will do :
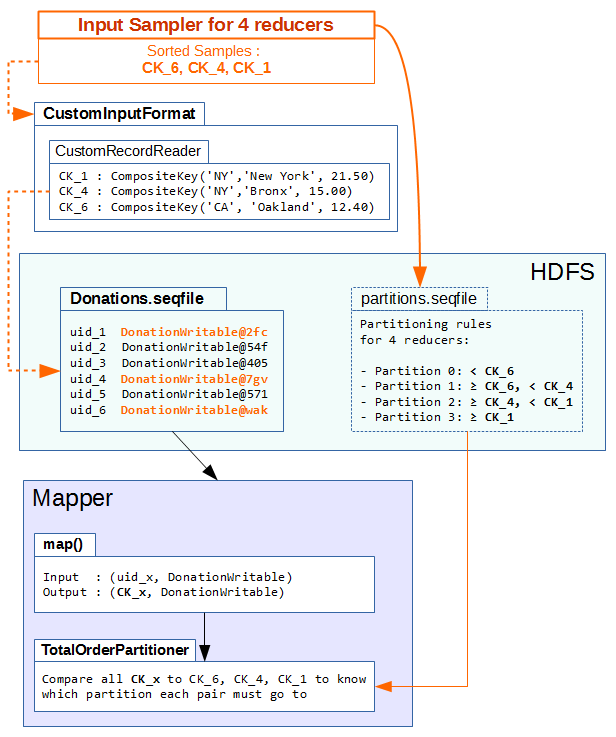
Optimization
Normally, the InputSampler reads the entire file and picks out random samples. But in our case this would be very costly, because we would have to read all 5 million DonationWritable objects (which contain over 20 fields) from the sequence file and create a new CompositeKey object each time. And most of these objects would be wasted, because the InputSampler would only pick a fraction of them.
That is why I decided to push down the sampling task to a lower level, during the record reading. This way, only randomly chosen records are subject to CompositeKey extraction.
So our custom RecordReader takes care of sampling before the InputSampler. But we still need to use an InputSampler to create the partitions file for the TotalOrderPartitioner. And if we used a RandomSampler, like in the previous section, it would pick random samples from our pre-sampled input data, which is a bit useless. So this time we will use a SplitSampler instead, to take all of the data coming from the InputFormat.
Also, since our data, the “donations” dataset, is unordered and seems to have a random distribution on the “state” field, we will limit the number of entries that will be read for sampling. We can do this because we will implement our own RecordReader. Taking samples from 500k records will be about two times faster than from 1 million records, and the samples should have a very similar value distribution in both cases.
MapReduce Solution
The MapReduce job code is here : https://github.com/nicomak/[…]/TotalSortByCompositeKey.java
The code is very similar to the job from the previous section, except that we now use the same input for sampling and map-reduce. The big difference with the previous job is not in the driver code, but in the custom InputFormat and RecordReader we implement.
The Custom InputFormat
The custom InputFormat class used here is CompositeKeySamplingInputFormat (view).
It extends the SequenceFileInputFormat with generic types <CompositeKey, NullWritable> so that the “hack” described above can work.
Its main purpose is to manage configuration properties and use these values to create the custom RecordReader. The configurable properties are :
- nbSamples : number of samples to take.
- readLimit : number of records (starting from the beginning) to take samples from.
The Custom RecordReader
The custom RecordReader class is : CompositeKeySamplingRecordReader (view).
This is not a real implementation of a RecordReader. It is a fake record reader which encapsulates a real record reader, a SequenceFileRecordReader. It goes through all records from the sequence file reader, and does Reservoir Sampling to take a fixed number of samples nbSamples from the first readLimit records. It stores these samples as CompositeKey objects in an ArrayList and then serves them with the nextKeyValue() and getCurrentKey() method.
Read more about Reservoir Sampling on wikipedia.
Execution and Analysis
$ hadoop jar donors.jar mapreduce.donation.totalsecondarysort.TotalSortByCompositeKey \ donors/donations.seqfile \ donors/CK_partitions.seqfile \ donors/output_totalsecondarysort $ hdfs dfs -cat donors/CK_partitions.seqfile SEQ♠-mapreduce.donation.secondarysort.CompositeKey!org.apache.hadoop.io.NullWritable *org.apache.hadoop.io.compress.DefaultCodec 8bn87ØÃ٢d`¶93¥94 ↑ ☻IA ♫Guthrie CenterBÈ x9c♥ ↓ ◄ ☻NY merrickBú x9c♥ hduser $ hdfs dfs -ls -h donors/output_totalsecondarysort Found 4 items -rw-r--r-- 2 hduser supergroup 0 2016-01-04 19:23 donors/output_totalsecondarysort/_SUCCESS -rw-r--r-- 2 hduser supergroup 25.5 M 2016-01-04 19:23 donors/output_totalsecondarysort/part-r-00000 -rw-r--r-- 2 hduser supergroup 25.6 M 2016-01-04 19:23 donors/output_totalsecondarysort/part-r-00001 -rw-r--r-- 2 hduser supergroup 23.5 M 2016-01-04 19:23 donors/output_totalsecondarysort/part-r-00002 $ hdfs dfs -cat donors/output_totalsecondarysort/part-r-00000 | tail -n 3 abdbfb0723ed10d645a6b1e640e39a7c IA Griswold 50.00 5c0e8c1e43469f21c1e3d7a3bad9d0e0 IA Grundy Center 15.00 16cad9603710baf2f28831c407fa6d82 IA Grundy Center 10.00 $ hdfs dfs -cat donors/output_totalsecondarysort/part-r-00001 | head -n 3 84d6f8f7d009d12f1af4d62515528933 IA Guthrie Center 100.00 2c4c43d27e41e998fe5bcdca7d354070 IA Guttenberg 50.00 a53c56bcddaba10ce88a3c7a21407ed6 IA Guttenberg 25.00 $ hdfs dfs -cat donors/output_totalsecondarysort/part-r-00001 | tail -n 3 962053dd43680abce76de6c54a7d1906 NY MERRICK 200.00 70693bf78d1cbf001fd2b8953b1c3e01 NY MERRICK 189.29 be414a9671ed09cc6324d809fe2df239 NY Merrick 171.76 $ hdfs dfs -cat donors/output_totalsecondarysort/part-r-00002 | head -n 5 84ba84b338a8a9b0a972b523514ae351 NY merrick 125.00 d7cbba9d6710575e307a8ba1206a2aeb NY Merrick 122.25 73ea2b4390e8e363aa4d5ca5191662bf NY Merrick 116.47
This time, we can distinguish the following boundaries from the partitions sequence file :
- IA, Guthrie Center
- NY, merrick
The “total” donation amount field is supposed to be in there as well, but it’s probably not readable without decompression.
By checking how the output file were delimited, we can see that they indeed have “IA Guthrie Center 100.00” and “NY merrick 125.00” as boundaries.
This time the files are split on a specific (state,city,total) triplet, so “states” don’t need to be exclusive to a reducer. For example the “NY” state can be found in both outputs 00001 and 00002. This also gives better load balance, as the 3 output file have nearly the same file size.
The job took on average 2min 31s, which is similar as the Secondary Sort from the previous part.
Very nice post.
very well explanation of total order sort
Awesome!!
How your partition file gets distributed across nodes, without using distributed cache?